
Set 인터페이스는 중복이 없는 자료구조(집합)를 구현할 때 사용한다. 대표적으로 HashSet , LinkedHashSet ,TreeSet 이 있다. 이 글에선 각 특징과 각 구현체들의 성능을 비교해보았다.
HashSet vs LinkedHashSet vs TreeSet
각각의 특징은 다음과 같다. 정렬이 필요한 경우가 아니라면 속도가 빠른 HashSet을 사용하는 게 좋다.
- HashSet : 가장 빠름, 정렬X
- LinkedHashSet : 입력 순서대로 저장
- TreeSet : 값이 오름차순으로 정렬되어 저장
내부적으로 HashSet과 LinkedHashSet는 Hash 알고리즘으로 TreeSet은 Tree 알고리즘 (자세히는 RBT- 알고리즘)으로 구현되어 있다. 각 자세한 알고리즘은 링크에 정리해두었다.
- Hash 알고리즘
- Tree 알고리즘
아래 성능 비교할 때 더 자세히 다루겠지만, HashSet 과 LinkedHashSet는 Hash 구조이기에 검색 할때 키값으로 바로 접근하여 O(1)의 시간 복잡도를 가진다. 그리고 TreeSet은 Tree 구조이기에 검색시 최대 O(log N)의 시간 복잡도를 가진다.
참고로 Set은 중복X, 순서가 없는 자료구조라고 알고 있었는데, LinkedHashSet, TreeSet은 순서가 있잖아?? 할 수 있다. 근데 Set이 순서가 없단 말은 List처럼 배열의 인덱스에 순서가 없다는 의미이다. 즉 Set은 데이터가 정렬될 수는 있지만, Hash나 Tree같은 구조이고, List나 배열처럼 인덱스에 순서가 있는 구조는 아니다.
HashSet은 내부적으로 HashMap이다!
Hash는 Key와 Value가 일대일로 저장되는 자료구조이다. HashSet은 사실 내부적으로 HashMap으로 구현되어 있다. 인텔리제이를 통해 내부 구현을 살펴볼 수 있었다.
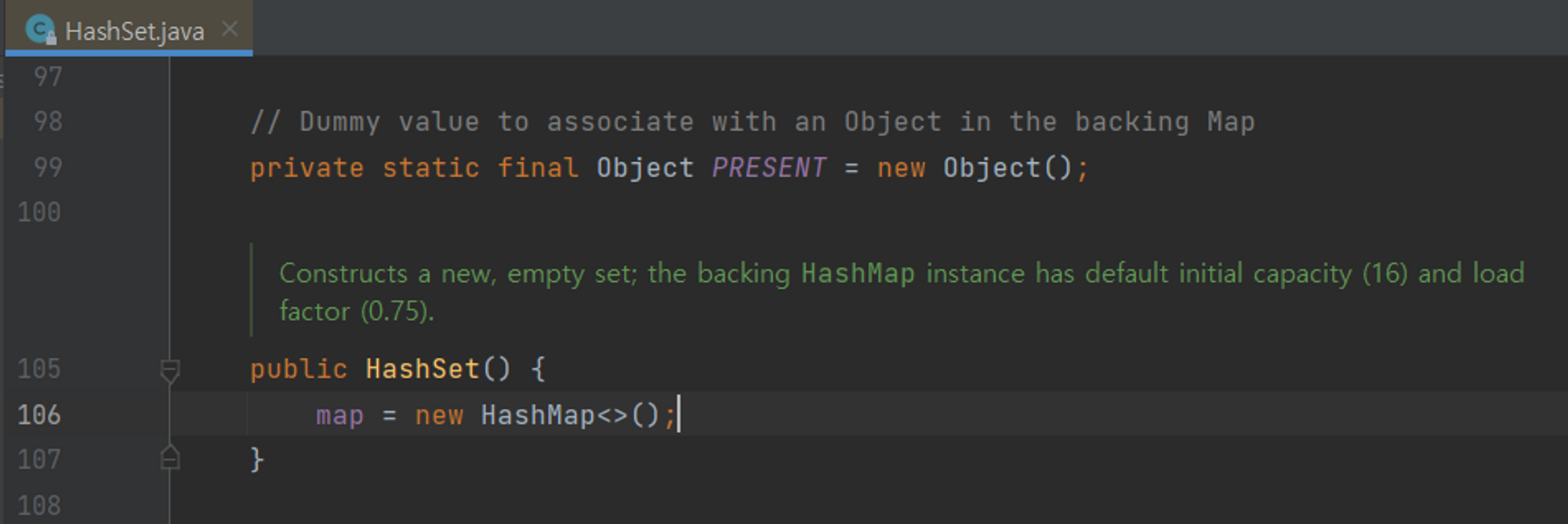
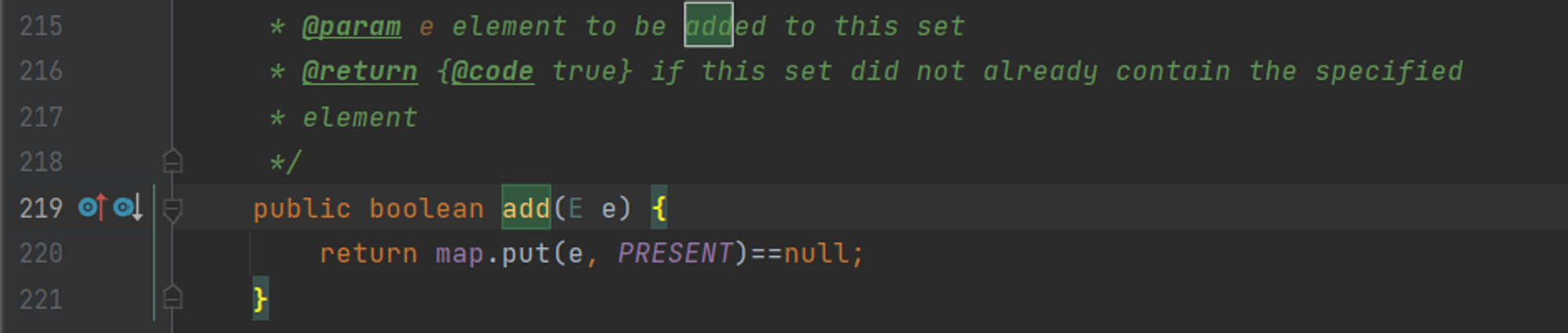
근데 HashMap같은 경우는 put(key, value)으로 사용자가 키와 값을 저장한다. 그럼 HashSet은 값을 어떻게 저장할까? Set은 add(데이터)으로 저장된다. 이때 사용자가 add하려는 데이터가 Key값이 되고, Dummy 객체가 Value로 저장된다. 이것도 인텔리제이를 통해 찾아볼 수 있었다.
- Value(값)으로 저장될 Dummy 객체

- add(데이터)는 사실put(데이터, 더미객체)로 저장된다.
성능 비교 - BenchMark
위에서 말한 대로 HashSet과 LinkedHashSet는 Hash 알고리즘으로 구현되어 있다. HashTable에 인덱스로 접근하기 때문에 삽입, 검색 시 O(1)의 시간 복잡도를 가진다. 그리고 TreeSet은 Tree 구조이기에 값을 계속 비교하면서 삽입, 검색한다. 최대 O(log N)의 시간 복잡도를 가진다.
실제 성능 비교를 해보기 위해 Gradle 프로젝트에서 JMH를 사용해서 벤치마크를 측정해보았다. 코드 전문은 아래 깃허브 링크를 통해 볼 수 있다.
- 삽입 연산일 때의 성능 비교
@Benchmark
public void addHashSet() {
hashSet = new HashSet<>();
for (int i = 0; i < COUNT; i++) {
Integer randomNumber = random.nextInt();
hashSet.add(randomNumber);
}
}
MILLISECONDS 밀리초로 평균 속도를 측정해보았다. 100개일 때는 사실 크게 차이가 나지 않아 보인다.
- 100개 삽입 연산

십만개, 백만개 정도로 하면, 차이가 보인다. Hash와 LinkedHash는 비슷하지만, TreeSet은 훨씬 오래 걸린다. 100_000 개 삽입 연산
- 1_000_000개 삽입 연산

2. 검색 연산일 때의 성능 비교
Set 컬렉션들은 검색 연산과 삭제 연산의 시간 복잡도가 같다. List라면 삭제 후 앞/뒤 요소들을 Shift해주어야 하기에 삭제 연산이 더 오래 걸린다. 하지만 Set은 List처럼 순서가 있는 자료구조가 아니기에 삭제 후 shift 해주는 과정이 불필요하다. Set 컬렉션에서 랜덤 값을 10_000번 검색하는 상황이다. (코드 전문은 깃허브 링크에 있다)
@Benchmark
public void containsHashSet() {
for (Integer searchNumber : randomNumbers) {
hashSet.contains(searchNumber);
}
}

TreeSet이 HashSet, LinkedHashSet보다 삽입이나 검색에서 느린건 맞게 나왔다. 근데 여기서 의문인 점이..왜 삽입보다 검색이 훨씬 오래 걸리는 걸까? 내 생각에선 삽입이면 매번 데이터를 정렬해서 검색보다 더 느릴 것 같았다..! 검색할 떄는 이미 정렬된 트리구조에서 데이터의 대소를 비교하면서 찾아가기 때문에 삽입 연산보다는 빠르지 않을 까 싶었다. 이 부분은 나중에 찾아서 알게되면 다시 글에 업데이트 할 예정이다!
Reference
- https://github.com/melix/jmh-gradle-plugin
- https://medium.com/swlh/introduction-to-treeset-and-treemap-5405f21124d
- https://www.geeksforgeeks.org/difference-and-similarities-between-hashset-linkedhashset-and-treeset-in-java/
- https://ysjee141.github.io/blog/quality/java-benchmark/