
DB Index를 공부하던 중, 이를 활용해서 실제 성능 개선을 확인해보고 싶었습니다. 이전 CAFEMATE 프로젝트에서 Index로 성능 개선해볼만한 기능이 있어 실제로 적용해보는 과정을 정리해보았습니다. 이 글에서는 MySQL에서 Index 생성하는 과정부터 Full Scan일 때와 Index 생성 후의 조회 성능을 비교해보았습니다.
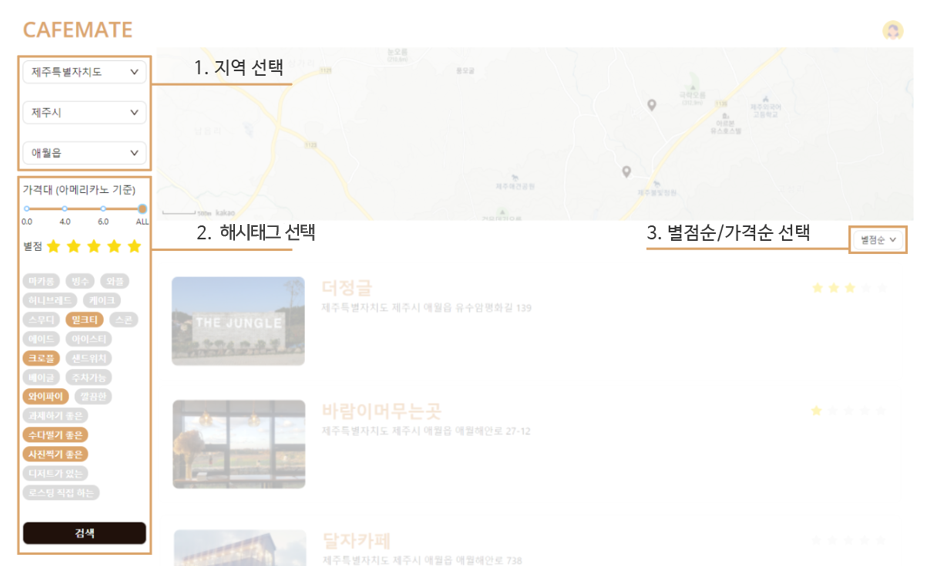
우선 카페 조회는 사용자가 지역을 선택하면 해당 지역의 카페 정보들이 조회됩니다. 예를 들어 ‘연남동’을 선택하면 연남동 카페들이 불러와집니다.
이때 ‘동’을 저장하는 컬럼(dong)에 인덱스를 생성하여 조회 속도를 개선시켜주려고 합니다. (이는 그림에서 1. 지역 선택에 해당합니다. 2. 태그 선택 3. 별점순/가격순 선택은 후에 다른 방식으로 속도 개선을 해보려합니다!!)
인덱스를 생성해주는 게 좋을까?
인덱스를 사용하는 게 ‘항상’ 좋은 방식은 아니지만, 해당 프로젝트에서 지역별 카페 조회하는 경우에는 인덱스 사용이 효율적이라 생각들었습니다. 그 이유를 몇 가지 정리해보면,
1. 데이터가 많다.
카페 데이터는 약 10,000개로, 많은 데이터가 저장되어 있습니다. 따라서 Full Scan하는 방식이 비효율적이었습니다.
2. 조회가 많고 삽입/삭제가 없다.
카페 정보들은 개발자가 사전에 크롤링하여 DB에 저장해두고, 후에 update하지 않습니다. 따라서 인덱스를 생성해주어도 update로 인한 추가 비용이 들지 않습니다.
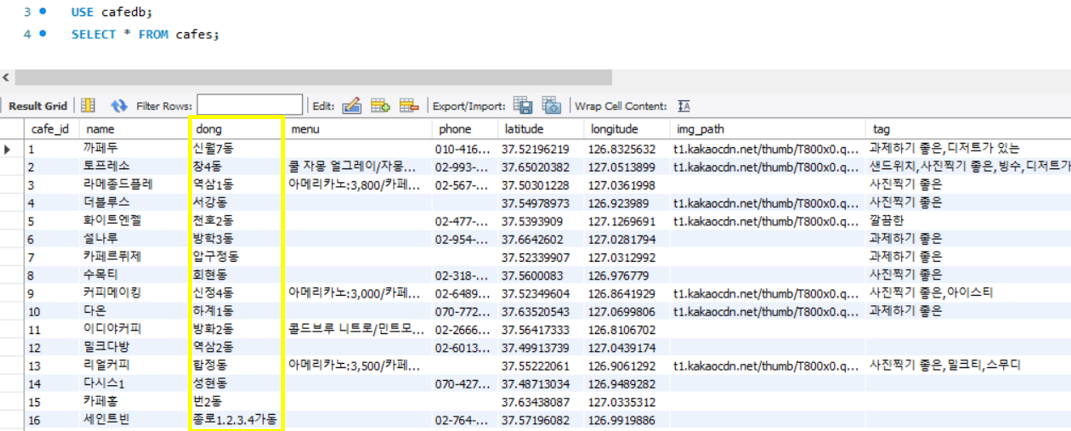
3. Cardinarty가 높다.
동 컬럼(dong)의 Cardinarty가 높은 편입니다. 즉, 중복되는 데이터가 많지 않아 인덱스를 만들어주는 게 Full Scan보다 효과적이었습니다.
참고로 Cardinarty는 해당 컬럼값의 종류 갯수입니다. 이를 통해서 해당 컬럼의 데이터들이 얼마나 많이 중복되었는지를 파악하기 위해 사용합니다. 예를 들면,
- 성별 컬럼의 경우, 남/여를 저장하므로 Cardinarty가 2입니다.
- 요일 컬럼같은 경우, 월~일을 저장하므로 Cardinarty가 7입니다.
- PK의 경우, 모든 row마다 unique한 숫자가 들어있으므로 Cardinarty가 해당 테이블의 row수와 같습니다.
인덱스는 Cardinarty가 높은 컬럼을 선택하는 게 효과적입니다. Cardinarty가 낮으면 Fulll Scan과 다르기 때문에, 속도 개선도 없고 오히려 인덱스를 생성하느라 공간을 낭비하게 되기 때문입니다!!
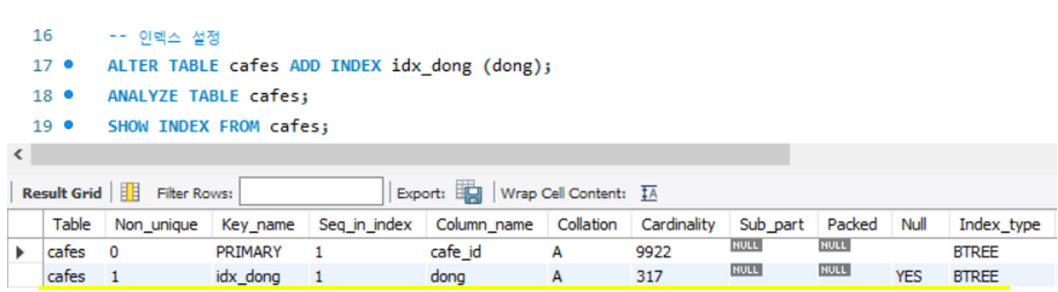
저의 경우 위의 그림에서 dong 컬럼의 Cardinarty가 317로 높기에 인덱스를 생성해주기 좋습니다.
이러한 세가지 이유로 인덱스를 생성해주는 게 효율적일거라 보았습니다. 따라서 기존에는 Full Scan을 하였지만, 동 컬럼(dong)에 인덱스를 생성해보고 성능을 비교해보겠습니다.
MySQL에서 인덱스 생성하기
이제 Full Scan하는 경우와 Index를 생성한 경우의 조회 속도를 비교해보겠습니다. 우선 Index를 생성해주지 않은 경우의 성능을 측정해보겠습니다.
1. Full Scan을 하게 되는 경우(보조 인덱스 설정X)
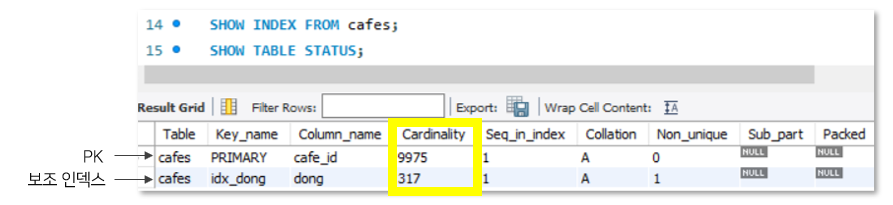
현재 테이블의 index 확인
현재 테이블의 index 목록을 보면, 기본적인 PK만 나옵니다.

연남동 카페 조회
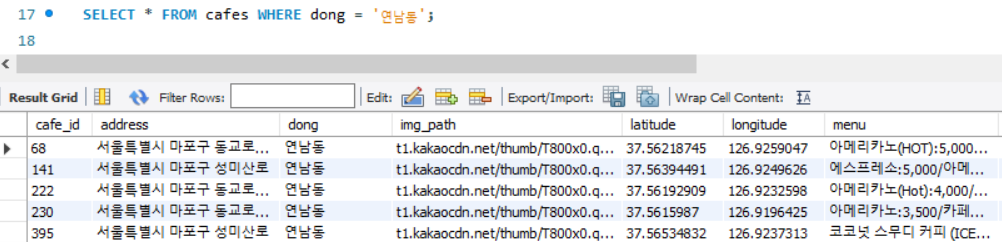
‘연남동’ 카페 조회 시, 테이블의 모든 row를 Full Scan하게 됩니다. 즉, 테이블의 처음부터 끝까지 ‘dong’ 컬럼 값이 ‘연남동’인 row를 모두 찾습니다.
EXPLAIN으로 성능 측정
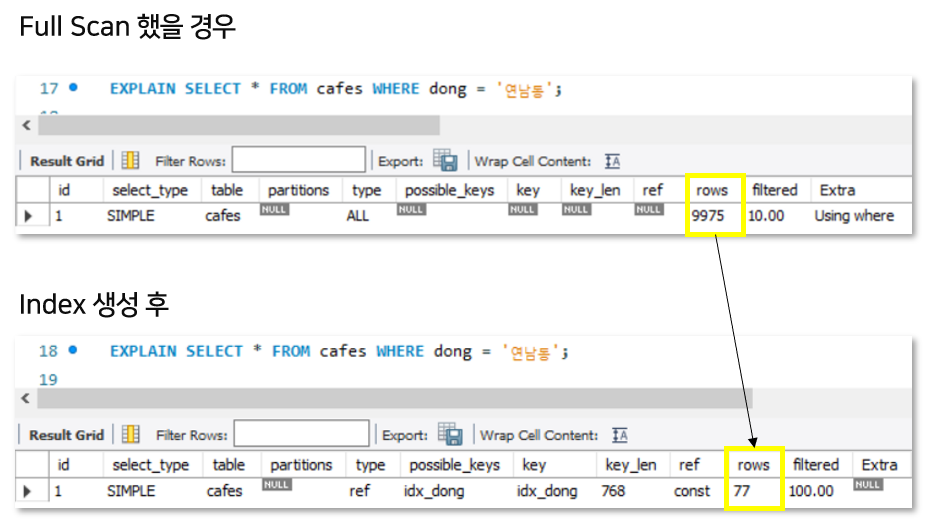
이때, EXPLAIN을 앞에 붙여주면 해당 쿼리의 성능/탐색 쿼리 수 등을 확인할 수 있습니다. row 컬럼은 해당 쿼리 실행할 때 탐색한 row수를 뜻합니다! 현재 9975 row를 탐색했다고 나옵니다.

MySQL의 Excution Plan으로 성능 측정
MySQL에서는 Excution Plan에서 Visusal Explain을 통해서 해당 쿼리를 시각적으로 확인할 수 있습니다.
SELECT * FROM cafes WHERE dong = '연남동';쿼리 실행 후,Excution Plan클릭 >Visusal Explain
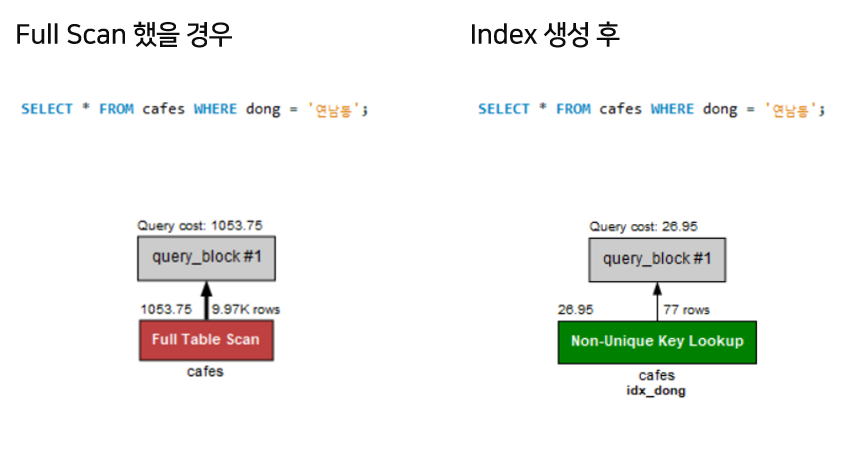
아래처럼 Visusal Explain을 통해서 탐색 row수, Query cost, 탐색 방식을 시각적으로 확인할 수 있습니다. 여기서 Query cost는 MySQL에서 측정한 쿼리 실행 비용으로, 여러 요인(cpu 등)들을 합산하여 계산한 비용이라고 합니다. 보통 1,000 - 100,000이 평균치이고 그 이상을 넘어가면 비싼 쿼리라고 합니다.
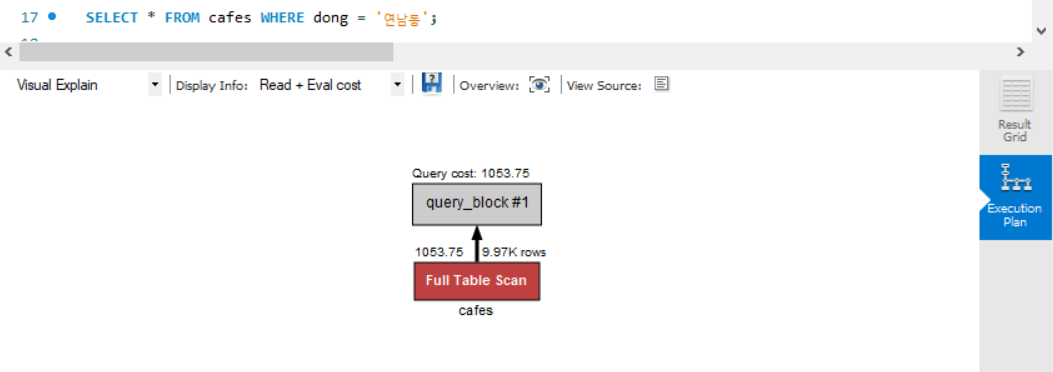
현재 Full Scan 방식에서는
- 탐색 row수는 아까처럼
9.97K(9975)가 나오고, - Query cost는
1053.75가 나왔습니다. - 그리고
Full Table Scan이라고 나옵니다.
위 자료들로도 성능을 측정해볼 수 있지만, 사용자 입장에서 더 와닿는 지표는 실행 시간일테니 시간을 측정해보겠습니다.
MySQL의 PROFILE으로 쿼리 시간 측정
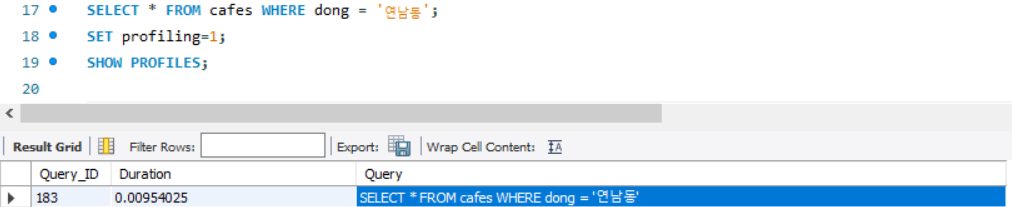
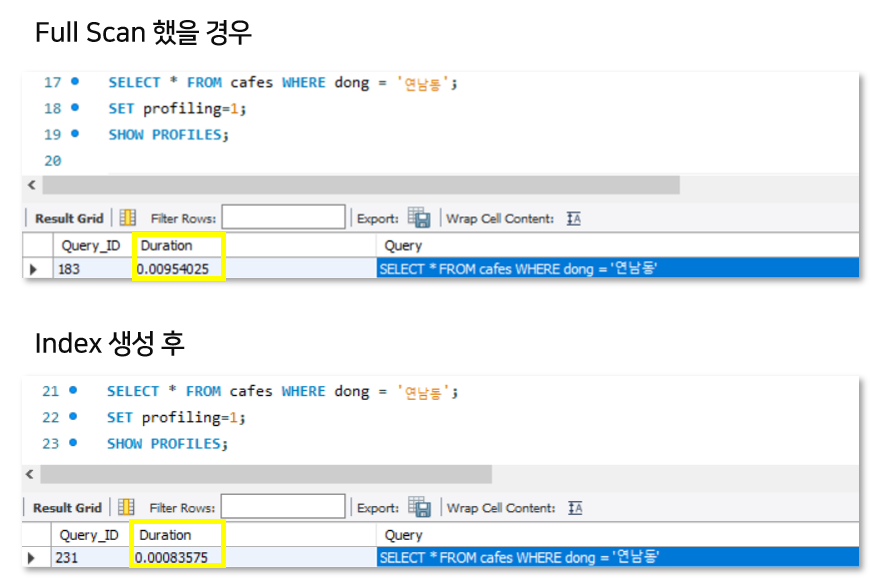
MySQL의 PROFILE을 사용하면 실행한 쿼리의 시간을 측정해볼 수 있습니다. 아래의 쿼리를 실행하면 최근 15개 쿼리의 실행 속도를 확인할 수 있습니다. (sec단위)
SET profiling=1;SHOW PROFILES;
현재는 0.0095sec가 나왔습니다.
Postman으로 조회 속도 측정
마지막으로 실제 API 호출 시 실행속도를 확인해보겠습니다. 위에서의 시간은 서버가 없이 단순 쿼리의 실행시간만을 측정한 상황입니다. 실제로는 Spring 서버를 거쳐 조회를 하므로 Postman을 사용하여 시간을 측정해보겠습니다.
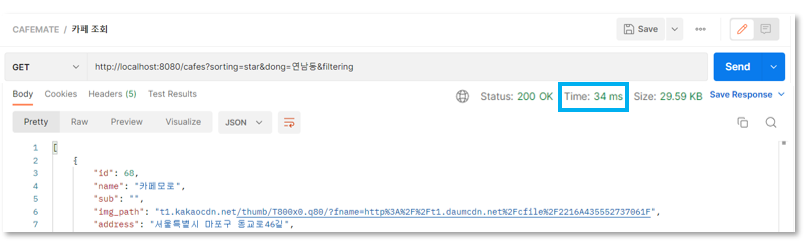
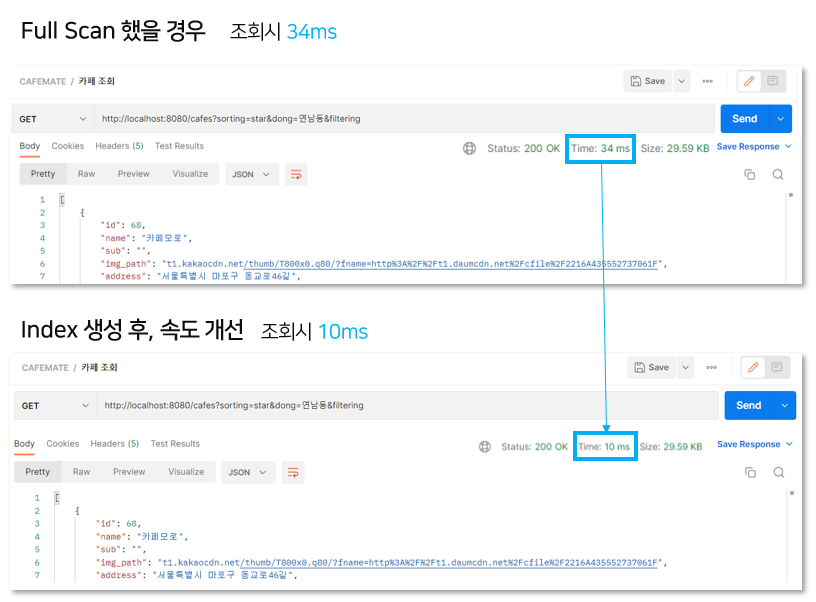
Full Scan을 하면 아래 그림처럼 34ms가 걸리는 걸 확인해볼 수 있습니다. 최초 조회 시에는 300ms정도가 나왔는데, 처음 이후부터는 30~40ms가 나와서 최초 조회 시간은 평균에서 제외했습니다. (DB 처음 셋팅? 때문인지 최초 조회할 때 평균과 다르게 유독 시간이 크게 나오는 건 이유를 찾아봐야겠습니다 🤓 여러번 다시 셋팅해도 최초 조회할 때만 크게 나왔습니다..!)
2. Index를 생성한 경우
Index 생성
이제는 ‘dong’ 컬럼에 보조 인덱스를 생성하고, 이전과의 성능을 비교해보겠습니다.
ALTER TABLE cafes ADD INDEX idx_dong (dong);// 인덱스 생성ANALYZE TABLE cafes;// 인덱스를 생성하고 이 쿼리를 해주어야 반영됩니다!SHOW INDEX FROM cafes;// 해당 테이블의 index 정보 확인
위 쿼리를 실행하면, 새롭게 dong 컬럼이 idx_dong이라는 이름의 인덱스가 추가되었습니다.
성능 비교 - EXPLAIN
이제 이전과의 성능을 비교해보겠습니다. 우선 EXPLAIN으로 탐색 row를 비교해보겠습니다. 이전에는 전체 row(9975)를 탐색한 반면, 인덱스 생성 후에는 77 row를 탐색하였습니다.
성능 비교 - MySQL Workbench의 Excution Plan
그리고 다음으로는 MySQL Workbench의 Excution Plan 중 Visusal Explain으로 쿼리 실행 과정을 시각적으로 비교 해보겠습니다.
- Query cost는
1053 → 26으로 줄어들었고, - 탐색 row수도
9.97K -> 77로 훨씬 줄어들었습니다. (위의 Explain으로도 확인해보았듯이) - 그리고
Full Table Scan에서Non-Unique Key Lookup으로 변경되었습니다.
성능 비교 - MySQL의 PROFILE으로 시간 비교
이제 더 와닿는 지표인, 시간을 비교해보겠습니다. MySQL의 PROFILE을 통해서 시간을 측정해보겠습니다. 일단 위에서 탐색 row수나 Query cost가 훨씬 감소했으니, 실행속도도 개선되었으리라 기대됩니다.
SET profiling=1;SHOW PROFILES;
Duration(쿼리 실행속도)이 0.0095sec → 0.0008sec으로 개선되었습니다!
성능 비교 - Postman
이번에는 Postman을 통해 카페 조회시 실행 시간을 비교해보겠습니다. Postman 테스트의 경우 Spring 서버를 거쳐 클라이언트에게 전달되는 속도이므로 더 의미있는 시간 측정이라 볼 수 있습니다.
Full Scan을 했을 경우에는 34ms가 걸렸는데, Index 생성 후에는 10ms으로 속도가 240%만큼 개선되었습니다(!!) 참고로 각 시간(34ms, 10ms)은 10~20회 시행후 측정한 값의 평균입니다.
생각보다도 더 개선되어 신기했습니다 😎
 DB에서 Index 이론 공부하면서 속도가 개선된다는 걸 알았지만, 실제 눈으로 확인해보니 생각보다도 더 큰 차이가 나서 신기했습니다. 데이터가 총 10,000개 일때 이 정도의 개선이면, 아마 더 큰 서비스에서는 더 효과적일 것 같습니다. ⚡
DB에서 Index 이론 공부하면서 속도가 개선된다는 걸 알았지만, 실제 눈으로 확인해보니 생각보다도 더 큰 차이가 나서 신기했습니다. 데이터가 총 10,000개 일때 이 정도의 개선이면, 아마 더 큰 서비스에서는 더 효과적일 것 같습니다. ⚡
다음 글에서는 해당 프로젝트의 조회 성능을 개선하기 위해 해시태그 관련 DB를 재설계해보겠습니다! 🤓