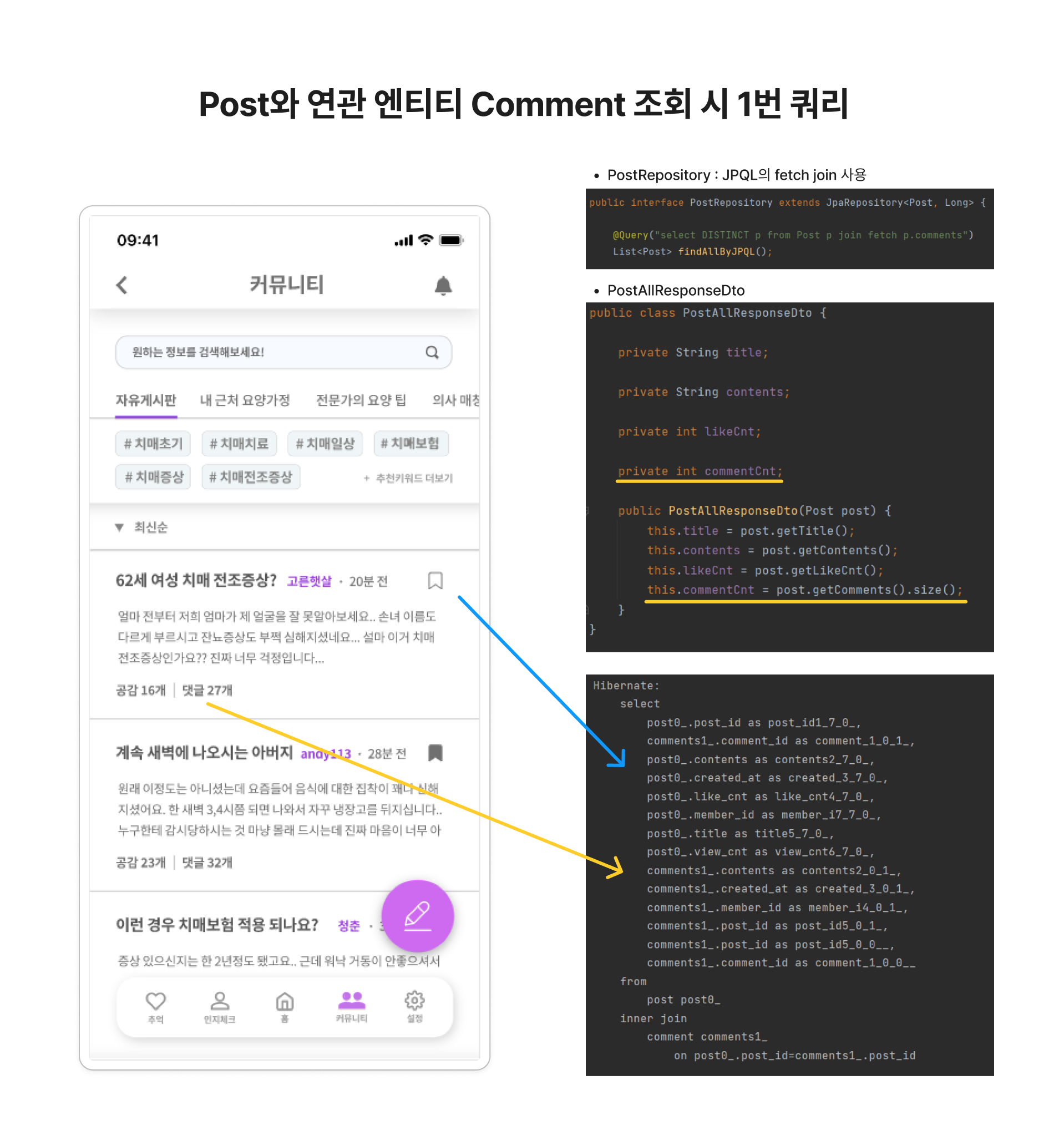
프로젝트에서 Post와 그 연관 엔티티인 Comment의 정보도 함께 조회해오는 기능을 구현하던 중 N+1 쿼리가 발생하였습니다. (Post : Comment = 1 : N 관계입니다) 즉시 로딩을 하면 추가 쿼리가 발생한다고 알고 있어서 지연 로딩으로 설정해주었습니다. 근데 지연 로딩으로 설정해주어도 로그를 확인해보면 N+1 문제가 발생하였습니다.
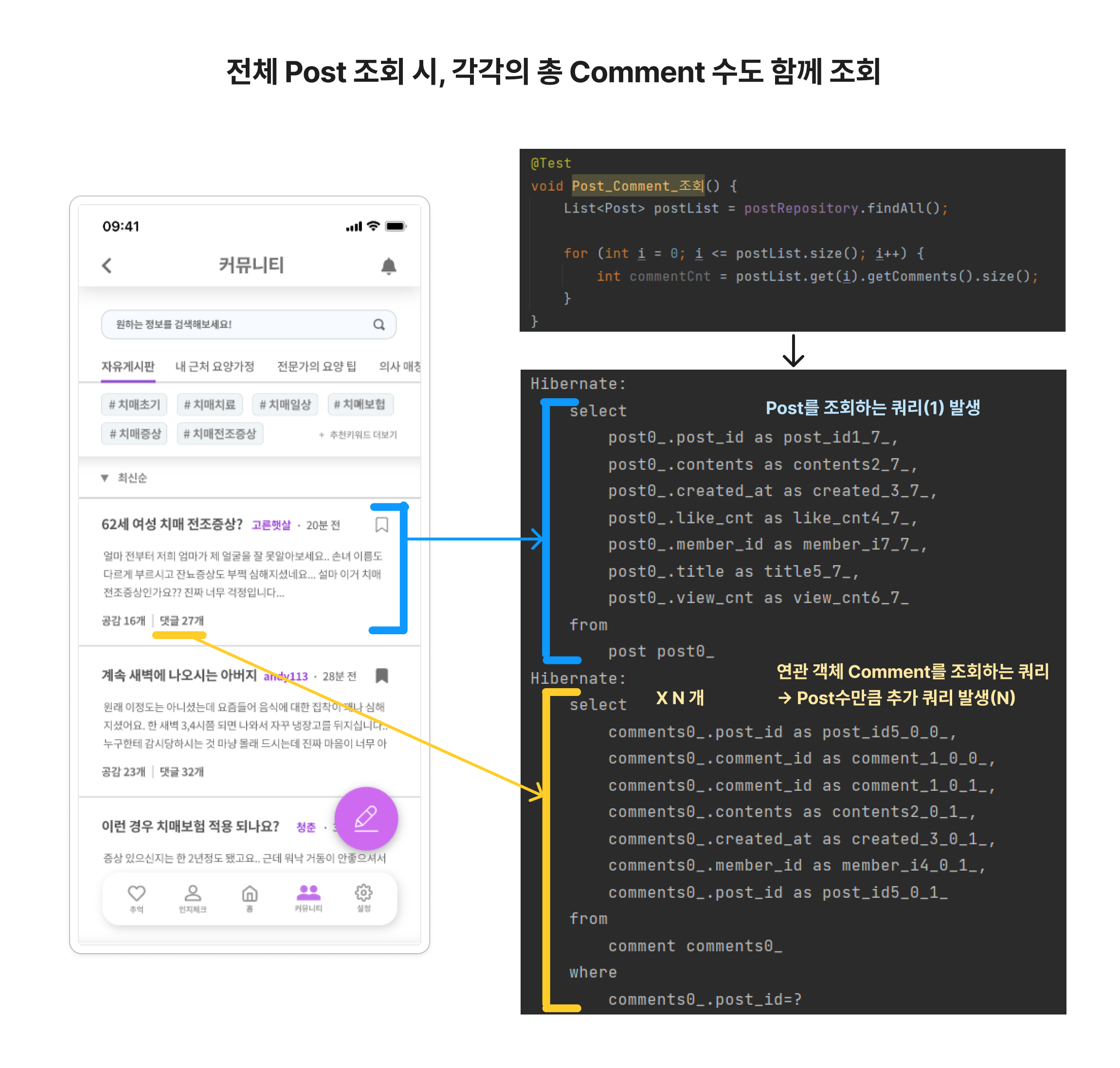
문제 상황은 아래처럼 전체 게시글 조회를 해줄 때, Post별로 총 Comment 갯수를 조회해오는 API입니다. 이때 지연로딩으로 설정해주었는데도 N+1 쿼리가 발생하였습니다.
이를 해결하기 위해 N+1 문제의 원인과 상황별 해결방법을 알아보겠습니다.
N+1 쿼리 문제란,
1번의 쿼리를 의도했지만, 연관 객체까지 추가적으로 조회(N번)되는 문제를 뜻합니다. N+1 문제가 발생하는 상황을 즉시 로딩/지연 로딩과 함께 알아보겠습니다.
지연 로딩 vs 즉시 로딩 - 언제 N+1이 발생할까
- 즉시 로딩 : 연관 관계에 있는 객체까지 바로 조회
- 지연 로딩 : 연관 객체를 프록시로 조회하고, 실제 사용할 때 DB에서 조회
기본적으로 즉시 로딩은 항상 연관 엔티티와 조인하여 조회합니다. 따라서 연관 엔티티를 검색하지 않더라도, N+1 쿼리가 발생합니다. 예를 들면, Post만 조회해오는 경우에도 연관된 객체 엔티티를 모두 조인하기 때문에 쿼리가 N+1개 발생합니다. 이론적으로는 두 테이블이 자주 조인을 하면 즉시 로딩을 사용하는 게 좋지만, 사실상 실무에서는 성능상 즉시 로딩은 사용하지 않는 다고 알고 있습니다.
반면 지연 로딩은 연관 엔티티를 검색하지 않고 Post 정보만 조회해올 경우, 연관 객체들을 프록시로 바인딩하기 때문에 총 1번의 쿼리만 발생합니다. 문제는 지연 로딩일 때 Post의 연관 엔티티인 Comment도 함께 조회해오면, N번의 쿼리가 추가 발생하게 됩니다! 각각의 상황에 대하여 로그와 함께 더 자세히 살펴보겠습니다.
즉시 로딩
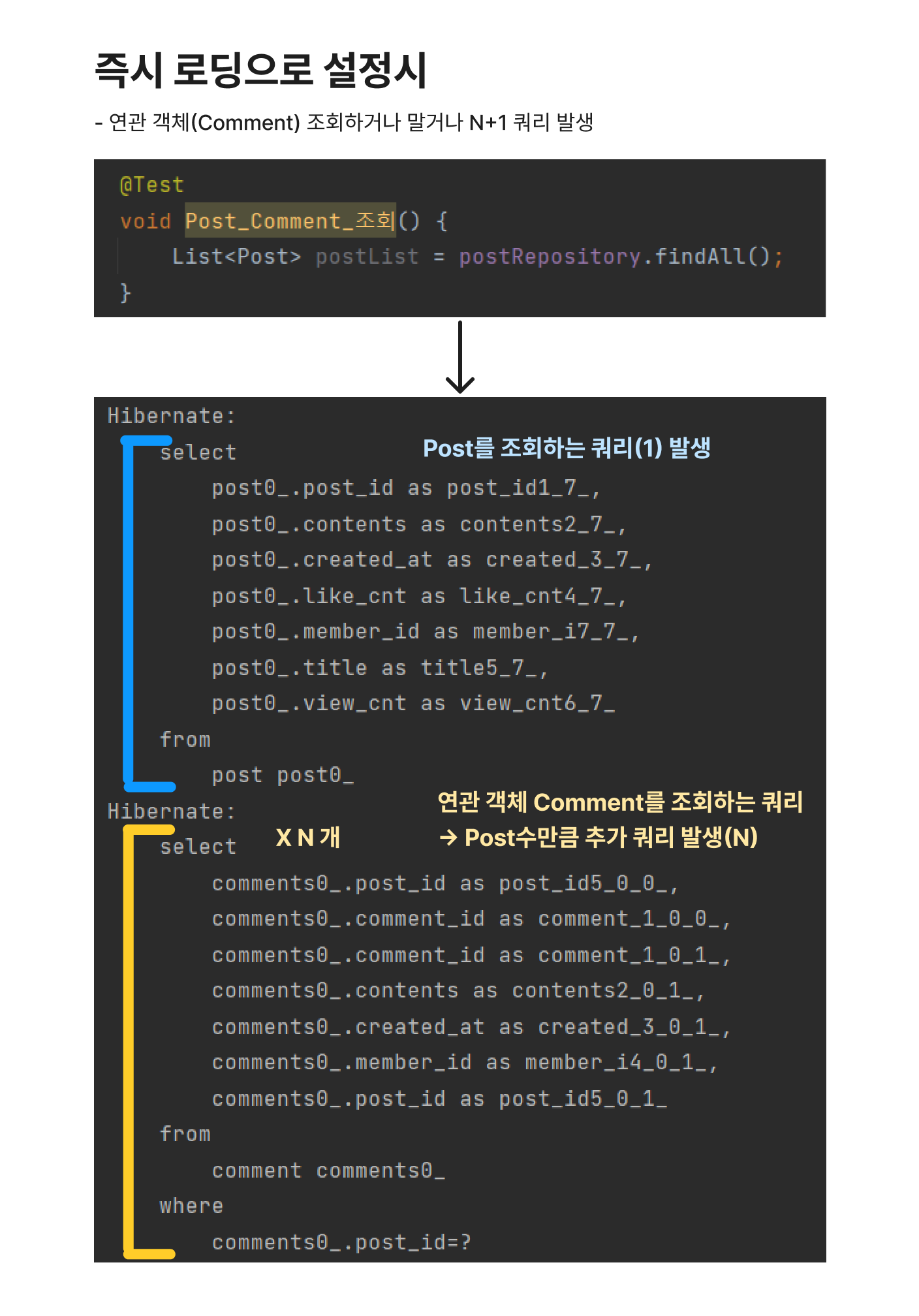
- 연관 객체를 조회하던 아니던 항상 N+1번 쿼리 발생
Post : Comment = 1 : N 관계일 때 EAGER 즉시로딩으로 설정하였을 경우, 항상 N+1 쿼리가 발생합니다. 즉 Post 1명을 조회해올 경우, 각각의 Post 별로 연관 객체인 Comment를 조회해오는 쿼리(N)가 항상 발생합니다. 따라서 만약 Post가 n만 개이면, Post 정보만 가져오더라도 불필요한 Comment 조회 쿼리(N개)가 추가 발생하게 됩니다.
지연 로딩
1. 연관 객체를 실제 사용하지 않을 경우 - 1번의 쿼리 발생
지연 로딩은 즉시 로딩과 다르게 프록시 객체로 바인딩하는 방식입니다. 실제 객체를 사용하지 않는 다면 DB 조회를 미루는 방식이므로, 이때는 1번의 쿼리만 발생합니다. 만약 Post 조회할 때 Comment 정보가 필요하지 않다면, 지연 로딩을 사용하는 것이 효율적입니다.
2. 연관 객체를 실제 사용할 경우 - N+1 번 쿼리 발생
하지만 만약 연관 객체를 실제 사용할 경우, User별로 Post 객체를 조회해오는 N번의 쿼리가 추가 발생합니다. 사실상 즉시로딩과 지연로딩의 차이는 실제 객체이냐 프록시 객체이냐의 차이일뿐, 연관 엔티티를 조회해올 때는 둘 다 추가적인 N번의 쿼리가 발생하게 됩니다!
다음의 예시를 보면,

이처럼 연관 엔티티를 조회할지 않을 때는 지연 로딩이 효율적입니다. 그럼 연관 엔티티를 조회할 때는 어떤 방식을 사용해야 추가적인 N번의 쿼리가 발생하지 않을까요? 우선 여기까지의 내용을 정리해보겠습니다.
N+1 쿼리 문제가 언제 발생하나?
N+1 쿼리 문제는 1번의 쿼리를 의도했지만, 연관 객체까지 추가적으로 조회(N번)되는 문제를 입니다. 그리고 다음과 같은 상황에서 N+1 문제가 발생합니다.
- 즉시 로딩을 사용하는 경우
- 지연 로딩을 사용할 때 연관객체를 조회하는 경우
N+1은 성능 저하를 일으킬 수 있습니다. 그럼 이를 해결하려면 어떻게 해야할까요?
먼저 즉시 로딩의 경우를 생각해보겠습니다. 만약 두 엔티티가 조인되어 조회되는 경우가 훨씬 많은 경우 사용하면 좋지만, 사실상 이는 이론적인 개념이고 실무에서는 성능적인 이유로 지연 로딩이 권장된다고 합니다.
그렇다면 지연 로딩을 사용한다고 가정해보겠습니다. 지연 로딩을 사용할 때 Post객체만 조회하고 그 연관 객체인 Comment를 조회하지 않는 다면, N+1 문제가 발생하지 않습니다. Comment를 프록시 객체로 바인딩하고, 실제 DB에 쿼리를 날리지는 않기 때문입니다. 따라서 기본적으로는 모두 지연로딩으로 설정해주는 게 좋은 방법이라고 합니다.
그럼 문제는 지연 로딩을 사용하면서 Post와 그 연관 객체인 Comment도 조회하려하는 경우입니다. 이때 1+N 문제를 해결하려면 어떻게 해야할까요? 상황에 따라 몇 가지 해결방법이 있습니다.
-
1(Post)+N(Comment) 쿼리 대신, 1번의 쿼리로 Post와 Comment를 한꺼번에 조회하기 ⇒ JPQL의 fetch join
-
연관 객체는 지정한 n개까지만 조회하기 ⇒ Batch Size 설정
-
아예 Post와 Comment를 따로 조회하기 ⇒ Comment 조회용 DTO와 API를 따로 생성
각각의 경우에 대하여 자세히 알아보겠습니다.
해결 1. JPQL의 fetch join
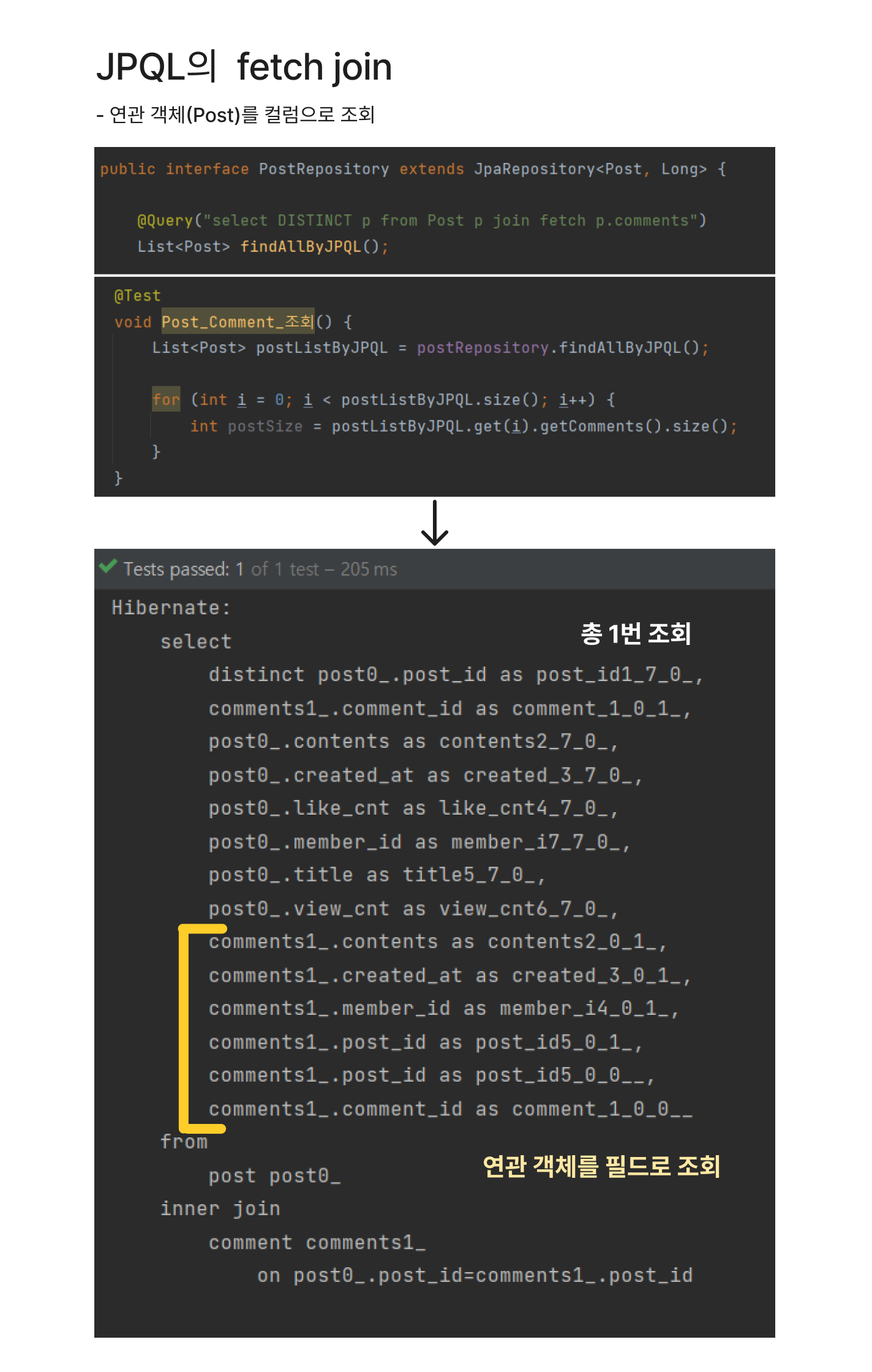
fetch join은 JPQL에서 성능 향상을 위해서 연관 엔티티를 한 번에 같이 조회하는 기능입니다. 참고로 이때 DISTINCT를 붙여주어야 합니다!! JPQL은 조인할 때 자동으로 중복 제거를 해주지 않기 때문에 DISTINCT를 붙여주어야 합니다. 아래처럼 총 1번의 쿼리로 Post와 그 연관 객체 Comment를 다 조회해옵니다.
fetch join의 단점
1. Paging API를 사용하지 못함
fetch join의 쿼리를 확인해보면, 연관 엔티티(Comment)의 모든 데이터를 조회해옵니다. 즉 이때 연관 객체들에 Paging API를 사용할 수 없고 모든 데이터를 한번에 조회해옵니다.
2. 연관 객체가 2개 이상인 경우 fetch join 사용 못함
fetch join은 컬렉션 * 컬렉션 카타시안 곱이 이루어져, 여러 연관 엔티티를 함께 사용할 수 없습니다.
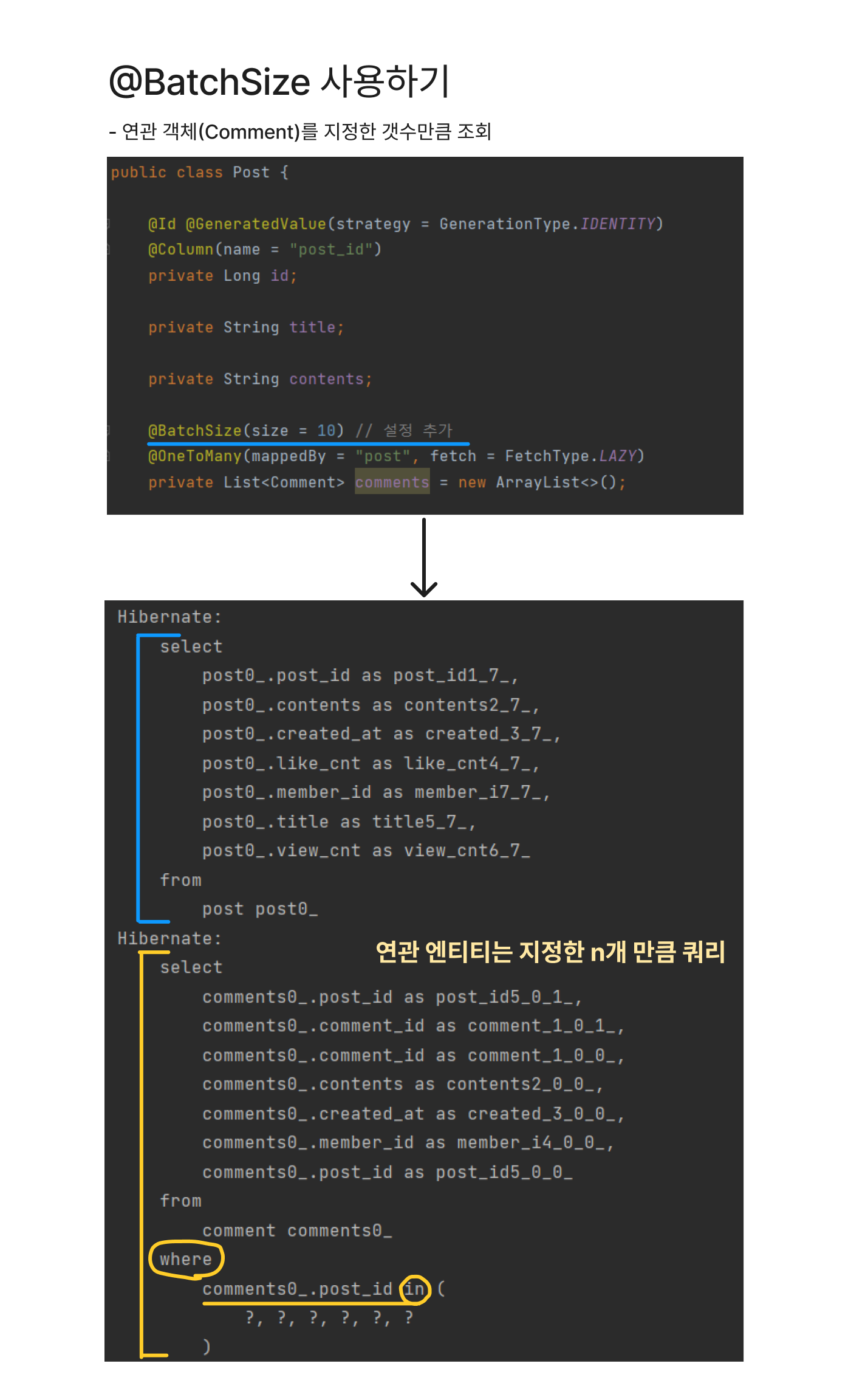
해결 2 : Batch Size 지정해주기
fetch join처럼 각 Post의 모든 Comment를 전체 조회하는 건 성능상 비효율적일 수 있습니다. 이때는 Hibernate의 @BatchSize을 사용하여 연관 엔티티의 조회 갯수를 지정할 수 있습니다.
만약 10개로 지정해주면, 각 Post당 10개까지의 Comment 엔티티가 (프록시가 아닌)실제 DB에서 조회해옵니다. 그리고 10번째 이후의 Comment 객체에 접근할 때는 다시 새 조회 쿼리가 발생한다고 합니다.
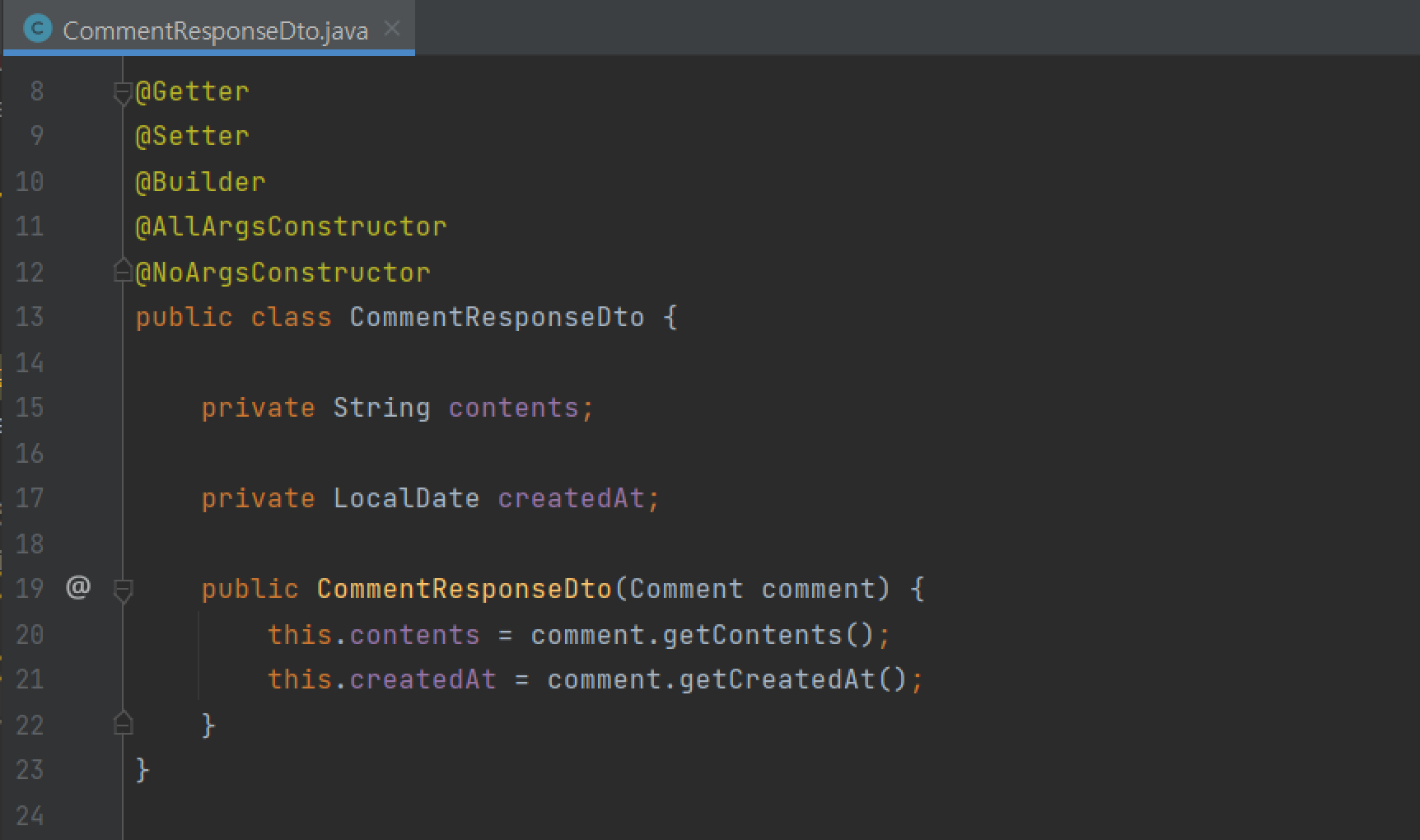
해결 3 : 새 DTO, API 생성해주기
만약 fetch join을 못 쓰는 상황인 경우(여러 엔티티를 함께 조회하거나, 페이징이 필요할 경우)에는 아예 새 DTO를 생성해주는 것도 방법입니다. 새로운 CommentDto를 설계하고 각 Post별 Comment를 조회해오는 API를 만들어 줄 수 있습니다. 이 경우에는 Comment 엔티티를 따로 페이징도 해줄 수 있습니다. 상황에 따라서는 Post와 Comment를 분리하여 다른 API에서 조회해오는 게 더욱 효율적일 수 있을 것 같습니다. (페이징도 가능하고 각각의 API가 가벼워지고 N+1 문제를 방지하므로)
정리해보면,
JPA에서 일대다/다대일 관계에서 즉시 로딩 혹은 지연 로딩 사용 시 연관 객체를 조회해올 때 N+1문제가 발생합니다. N+1은 한번의 쿼리를 의도했으나, 연관 객체들을 추가적으로 조회하는 N번의 쿼리가 추가적으로 발생하는 문제입니다. 이는 성능 저하로 이어지므로 상황에 맞게 해결해주어야 합니다.
기본적으로는 지연로딩을 설정해주되, 연관 엔티티도 함께 조회해올 경우 fetch join을 사용하는 게 N+1 문제를 방지하여 효율적입니다. 단, fetch join은 페이징이나 연관 엔티티를 2개 이상 조회해오지 못합니다. 또한, 연관 엔티티를 모두 조회해오기 때문에 오히려 더 비효율적일 수 있습니다. 이때는 연관 엔티티를 조회하는 갯수를 제한하는 BatchSize를 설정해주거나 DTO를 새로 생성해주는 게 효율적입니다.
- fetch join : 연관 엔티티 한번에 조회
- 페이징 안되고 연관 엔티티 2개이상 사용 불가
- 연관 엔티티를 모두 한번에 조회하므로 상황에 따라 오히려 비효율적일 수 있음
- Batchsize 설정 : 연관 엔티티 조회 갯수 설정
- DTO 새로 생성 : 아예 연관 엔티티는 따로 조회
현재 개발중인 API에서는 Comment 엔티티의 총 갯수만 필요하므로 페이징이 필요없고 BatchSize를 지정해주거나 DTO를 생성해줄 필요까지는 없었습니다. 따라서 다음처럼 fetch join만을 활용하여 조회 API를 구현해보았습니다.
- 관련 커밋(Remember Me 프로젝트) : https://github.com/GDSC-RememberMe/remember-me-server/commit/51f02b7aa51231a4c83d1cf71c8dcfb0e67e4869