
CS 공부하면서 배운 인덱스를 실제 프로젝트에 적용하여 조회 속도를 개선해보겠습니다. 우선 이번 글에서는 클러스터형 인덱스, 보조 인덱스, 커버링 인덱스의 개념과 인덱스를 언제 사용하는 게 좋을 지에 대하여 알아보겠습니다. 그리고 다음 글에서는 실제 프로젝트에 인덱스를 적용하여 속도를 개선해보겠습니다.
인덱스란
인덱스는 조회 성능을 높여주는 자료구조입니다. MySQL에서 인덱스는 B - Tree 구조로 이루어져 있습니다(이 글은 MySQL 위주로 작성하였습니다). 데이터베이스에서 B - tree를 사용하는 이유는 범위 탐색이 가능하기 때문입니다. Hash Table의 경우, 키값을 인덱스로 하여 바로 빠르게 접근할 수 있습니다. 하지만 Hash Table은 데이터가 정렬되어 있지 않기 때문에 범위 연산이 불가능합니다. 반면 B - tree는 데이터가 정렬되어 있습니다. 따라서 범위 탐색이 가능합니다.
또한 B - tree는 조회 시에 속도가 빠릅니다. 하지만 데이터를 변경하는 연산은 성능이 훨씬 떨어집니다. 상황에 따라 데이터 이동이나 페이지 분할 작업이 필요하기 때문입니다. 그래서 조회가 많은 경우에는 인덱스를 생성해주는 것이 유리하다고 볼 수 있습니다. 대부분의 서비스들은 다른 연산에 비해 조회 연산이 훨씬 많기 때문에 데이터베이스를 B - tree 구조를 사용한다고 합니다.
그럼 이제부터 클러스터형, 보조, 커버링 인덱스 각각에 대하여 자세히 알아보겠습니다.
1. 클러스터형 인덱스
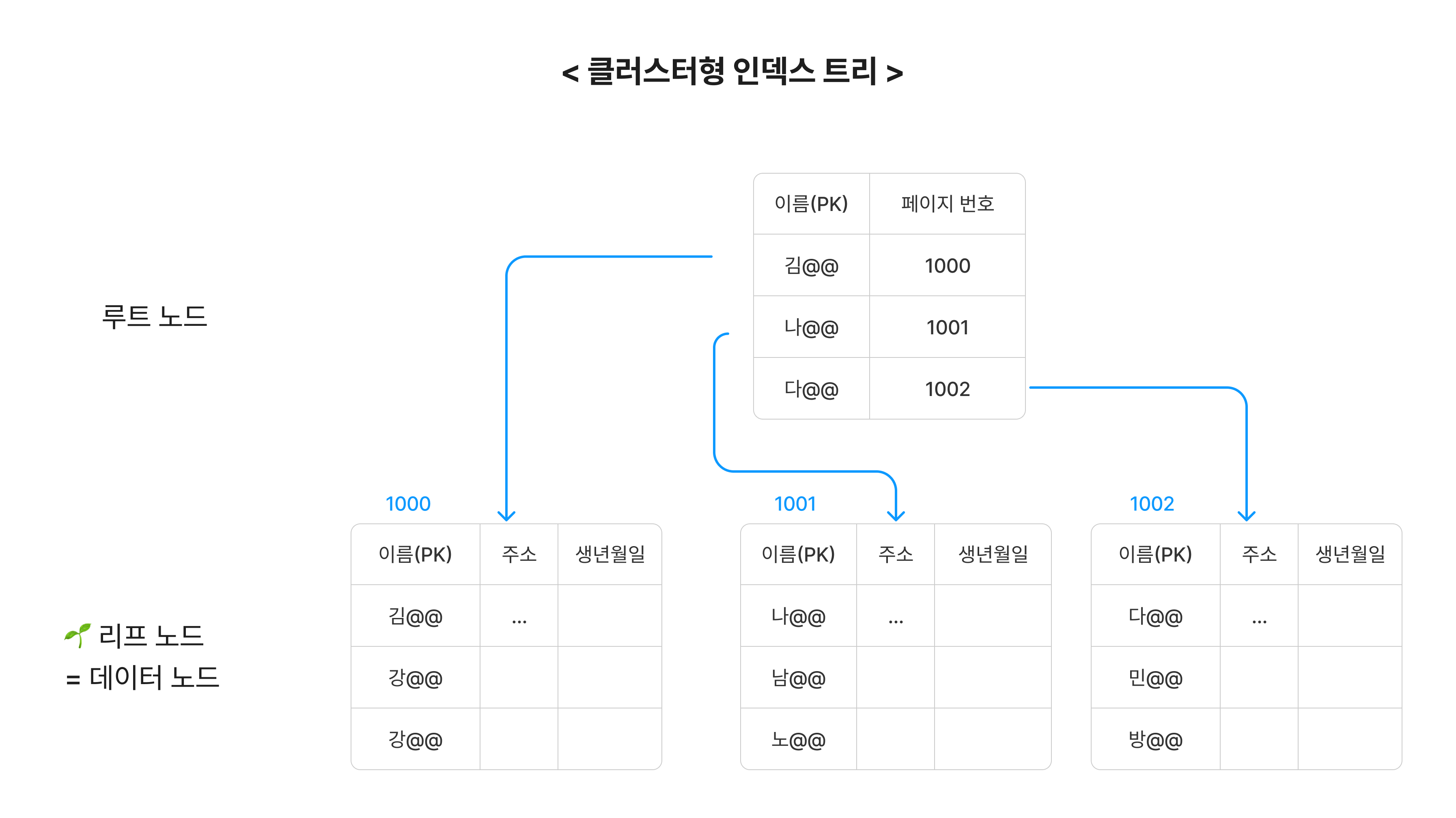
클러스터형 인덱스는 책의 목차와 같은 역할을 합니다. 데이터베이스는 클러스트형 인덱스를 기준으로 B - tree가 형성됩니다. 따라서 클러스트형 인덱스 트리의 마지막 리프노드가 실제 데이터 노드(실제 모든 column값이 있는 데이터)입니다. MySQL에서 PK를 설정해주면, 해당 column이 클러스터형 인덱스가 됩니다. 해당 column값을 기준으로 테이블의 모든 row가 자동 정렬됩니다.
참고로 그림에서는 중간 노드를 생략했지만, 더 큰 구조에서는 루트 노드와 리프 노드 사이에 중간 노드가 있습니다.
2. 보조 인덱스
보조 인덱스는 책의 마지막에 있는 색인과 같은 역할을 합니다. 보조 인덱스 페이지는 기존 데이터 페이지와는 별도로 형성됩니다.
우선 클러스터형 인덱스가 없는 상황에서 보조 인덱스를 생성한다고 가정해보겠습니다.(❗클러스터형이 있을 때와 없을 때의 보조 인덱스 트리가 다릅니다❗) 보조 인덱스 페이지의 리프노드에는 해당 row의 데이터 페이지에서의 위치(데이터 페이지 번호 + 오프셋)를 저장합니다. 즉, 해당 row가 어떤 페이지에, 얼마의 offset만큼 떨어져있는지 저장합니다.
예를 들어, 주소 column을 보조 인덱스로 설정해주면, 보조 인덱스 페이지는 주소를 기준으로 인덱스 트리를 형성합니다. 그리고 리프 노드에는 실제 row의 위치(데이터 페이지 + 오프셋)를 기록합니다.
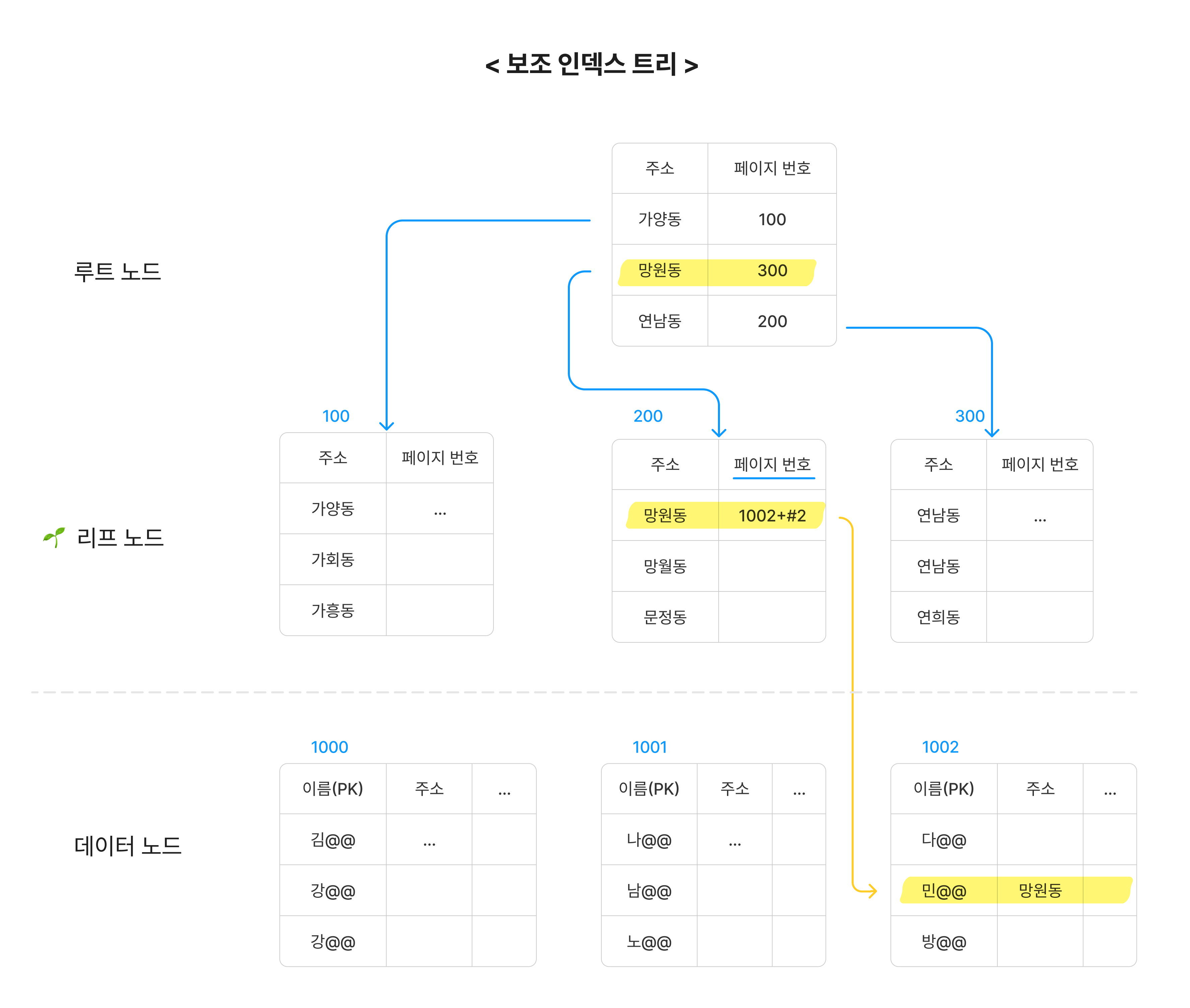
하지만 실제로는 클러스터형 인덱스와 보조 인덱스를 함께 사용하는 경우가 대부분입니다. 함께 사용하는 경우, 개념적으로는 위의 그림과 같지만 보조 인덱스 트리에 저장하는 값이 위치(데이터 페이지 번호+ 오프셋)가 아닌 “PK값”입니다. 이에 대해 그림과 함께 알아보겠습니다.
3. 클러스터형 + 보조 인덱스 함께 사용
아래는 실제로 클러스터형과 보조 인덱스가 함께 사용할 경우의 이미지입니다. 아까 그림과 달라진 점은, 보조 인덱스의 리프노드에 위치값(데이터 페이지 번호+ 오프셋)이 아니라 PK값이 들어갑니다.
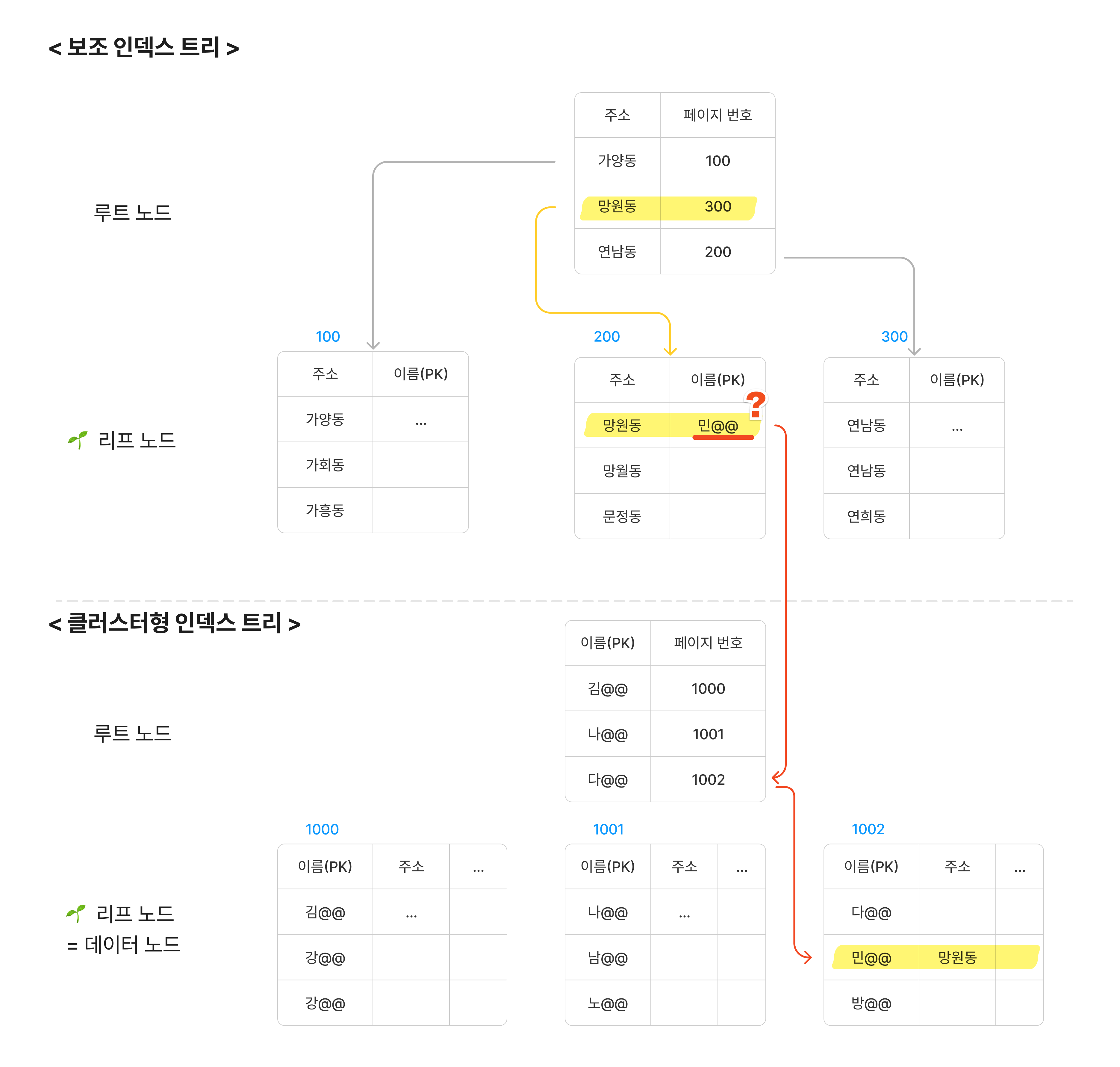
위치값(데이터 페이지 번호+ 오프셋)이 아닌 PK를 저장하는 이유는 무엇일까요? 만약 보조 인덱스 트리에 위치값을 저장하게 될 경우, 데이터의 변경/추가로 페이지 분할이 일어날 때마다 보조 인덱스 트리에도 위치값을 업데이트 해주어야합니다. 이에 발생하는 비용이 크기 때문에 위치값이 아닌 PK값을 저장합니다. 그리고 이 PK값으로 다시 클러스터형 인덱스 트리를 탐색하여 원하는 데이터 row를 조회하게 됩니다. 즉, 비용면에서 A < B 이기 때문에, A의 방식으로 인덱스 트리를 생성합니다.
- A. 보조 인덱스 트리 탐색(PK) + 다시 클러스터형 인덱스 트리 탐색(실제 row)하는 비용
- B. 보조 인덱스 트리 탐색(실제 row의 위치), 데이터 update마다 위치값(데이터 페이지 번호+ 오프셋)도 업데이트하는 비용
보조 인덱스를 사용하면 탐색하는 과정을 정리하면,
- 보조 인덱스 트리를 탐색하여 원하는 데이터의 PK값을 얻는다.
- 해당 PK값으로 다시 클러스터형 인덱스 트리를 탐색한다.
근데 위 그림을 보다보니 내가 원하는 정보의 PK값만 궁금하다면, 굳이 다시 클러스터형 인덱스 트리를 탐색할 필요가 없지 않을까 생각했습니다. 예를 들어 망원동에 거주하는 사람의 이름(PK)만 조회해올 때, 굳이 클러스터형 인덱스의 B - tree를 탐색할 필요가 없지 않나 생각이 들었습니다. 보조 인덱스 트리에 원하는 정보가 다 있기 때문입니다.
아예 보조 인덱스 트리에 PK가 아닌 한 두 개의 컬럼 값을 더 저장할 수 있다면, 보조 인덱스 트리만 탐색하고 클러스터형 인덱스 트리는 탐색하지 않아도 되지 않을까 생각이 듭니다. 이와 관련된 개념이 ‘커버링 인덱스’입니다.
클러스터형 vs 보조 인덱스 비교해보기
여기서 잠깐 커버링 인덱스로 넘어가기 전에 클러스터형과 보조 인덱스를 비교해보겠습니다.
클러스터형 인덱스
클러스터형 인덱스를 생성해주면, 데이터 페이지 전부가 해당 column을 기준으로 정렬됩니다. 그리고 리프 페이지 자체가 데이터 페이지입니다. 그래서 검색 속도는 보조 인덱스보다 빠릅니다. 하지만 데이터의 update/insert/delete 연산의 경우, 페이지 분할이 발생할수 있기 때문에 느립니다.
보조 인덱스
반면 보조 인덱스는 리프 페이지가 데이터 페이지가 아닙니다. 리프 페이지는 데이터 페이지의 위치 혹은 PK값을 저장하고 있습니다. 보조 인덱스는 검색하기 위해 실제 데이터 페이지를 또 접근해야 하기 때문에 속도가 느립니다. 하지만 보조 인덱스를 기준으로 실제 데이터가 정렬되지는 않기 때문에 데이터 update/insert/delete 시에 영향을 덜 받습니다.
클러스터형 인덱스가 탐색 속도가 더 빠르므로 어떤 데이터를 찾을 때, 가능하면 PK로 찾는 게 좋을 것 같습니다!✨ (같은 데이터를 찾을 때 다른 column보다는 PK로 찾는 게 빠르겠습니다.)
4. 커버링 인덱스
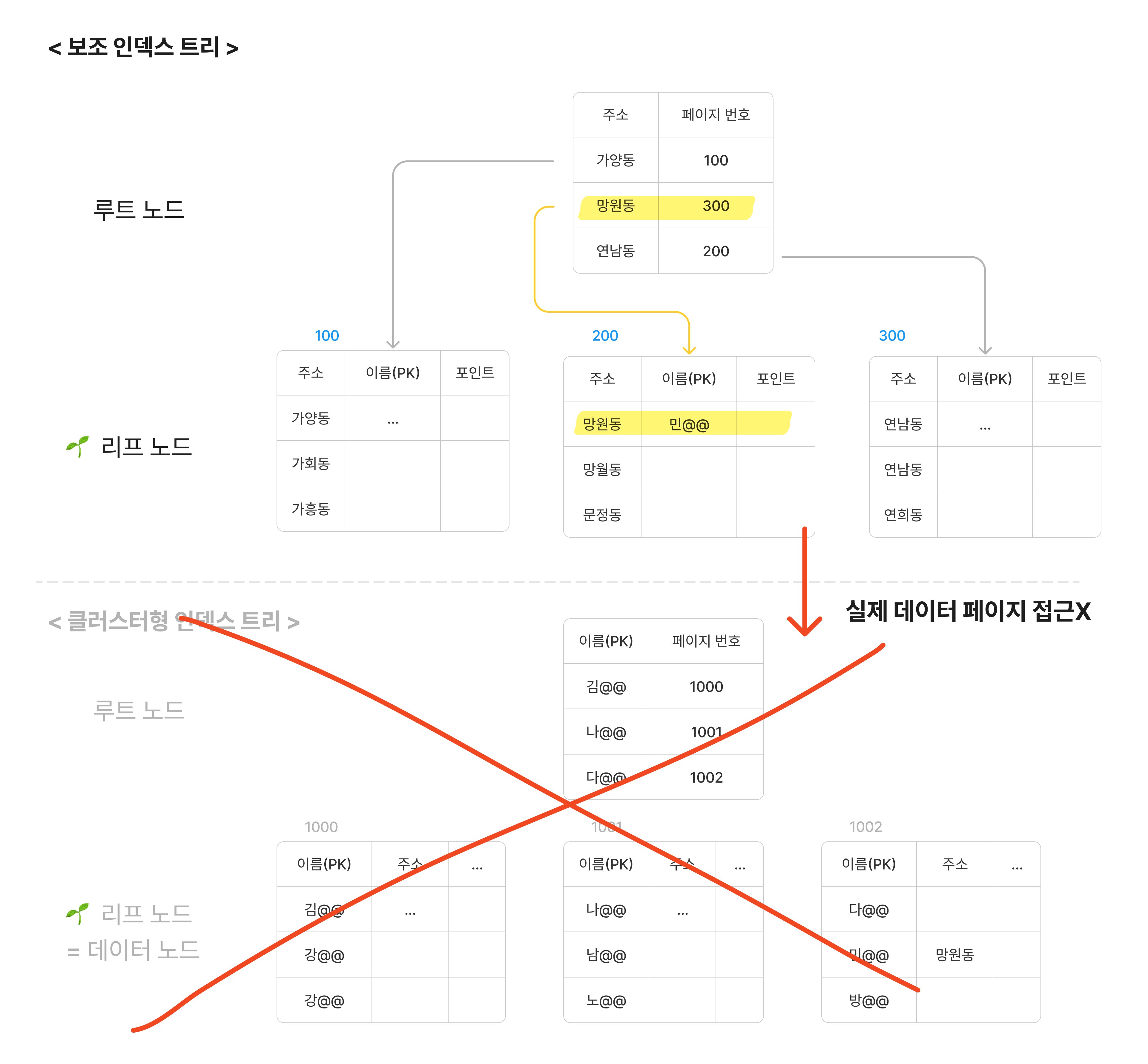
커버링 인덱스는 인덱스 트리에서 조회할 데이터를 모두 갖고 있는 인덱스입니다. 이를 통해 실제 데이터 페이지에 접근하지 않고 원하는 데이터를 조회할 수 있습니다. 보조 인덱스에 조회에 필요한 컬럼들을 모두 추가해주어 설정합니다.
예를 들어, 주소로 검색하면 해당 주소에 거주하는 사용자들의 이름과 포인트만 조회하고 싶은 상황을 가정해보겠습니다. 이럴 경우, 주소 column을 보조 인덱스로 설정하고, 이름과 포인트 column을 함께 인덱스 트리에 저장해주겠습니다. 그러면 주소 ‘망원동’을 검색 시, 인덱스 트리에서 원하는 이름과 포인트값을 함께 조회해올 수 있습니다. 굳이 실제 데이터 페이지를 탐색하지 않아도, 보조 인덱스 트리에 원하는 정보를 조회할 수 있기 때문에 검색 속도가 훨씬 단축됩니다. 단, 보조 인덱스 트리에 많은 컬럼을 두면 DB 리소스를 낭비하게 될 수 있으므로 상황에 따라 선택해주어야 합니다.
인덱스는 언제 사용해야 좋을까
사실 인덱스 생성 자체도 비용이 드는 작업입니다. DB 리소스를 차지하고, update 시에 인덱스 트리도 수정해주어야 하기 때문입니다. 따라서 인덱스는 꼭 필요한 상황에서 생성해주어야 합니다. DB 구조와 해당 서비스에서 어떤 쿼리를 많이 사용하는 지 등을 고려하여 주어야 합니다. 다음 3가지 경우를 모두 만족하는 column에 인덱스 생성해주는 게 좋습니다.
1. 전체 데이터 갯수가 많은 경우
인덱스 자체가 DB를 차지하므로 Full Scan하는 것보다 인덱스로 조회하는 게 효율적일 때 사용해야 합니다. 데이터가 많을 경우에 사용해주는 게 인덱스를 생성해주어야 합니다. (많다의 기준은.. 아마 )
2. 조회 연산이 update/insert/delete보다 훨씬 많을 경우
데이터를 update해주면, 페이지 분할/이동 등의 작업이 발생할 수 있습니다. 이때 인덱스 트리에도 매번 update해주어하므로 비용이 발생합니다. 따라서 데이터 update가 잘 발생하지 않고, 조회가 많이 발생하는 column에 인덱스를 생성해주는 게 좋습니다.
3. 카디널리티가 높을 경우 = 데이터 중복이 적을 경우
카디널리티는 데이터의 중복 수치를 뜻합니다. 예를 들어 성별 column은 2(남/여), 요일 column은 7(월~일)입니다. 만약 성별 column에 인덱스를 생성해주면, 사실상 Full Scan하는 것과 크게 다르지 않습니다. 오히려 인덱스 생성 비용이 발생하므로 비효율적입니다. 그래서 데이터가 중복되지 않는 column에 사용하는 게 좋습니다.
추가적으로 MySQL에서 인덱스는 다음 column에 자동 생성됩니다.
- PK 설정해주면 자동으로 클러스터형 인덱스가 자동 생성됩니다.
- UNIQUE, FK 설정해주면 자동으로 보조 인덱스 트리가 생성됩니다.
이어지는 글에서는 진행중인 프로젝트에서 보조 인덱스와 커버링 인덱스를 사용하여 검색 속도를 개선해보겠습니다.