
검색어 자동완성 기능 구현하는 과정에서 시간복잡도 개선, 트라이 자료구조(vs 이진탐색)를 활용한 탐색법, 문제를 발견하고 해결법을 선택하는 과정 등이 재밌어보여서 정리해보았습니다. 책 <가상 면접 사례로 배우는 대규모 시스템 설게 기초>을 참고하였고, 어려운 부분은 내용 추가하여 정리해보았습니다. 프로젝트 성능 개선을 하려면 어떤 식으로 접근/사고하는지 몰라서 막막했었는데, 이 책에는 대규모를 가정하고 문제 해결하는 사고 과정이 담겨있어서 재밌었습니다.
이후에 프로젝트에도 실제 도입해볼 수 있으면 해당 프로젝트에 맞게 다시 변형 적용해보고 다른 글로 정리해보겠습니다. 찾아보니 검색어 자동완성은 Elasticsearch을 통해서 많이 구현하는 것 같은데(..), 엘라스틱 서치는 이후에 추가적으로 찾아봐야 할 것 같습니다..!
이번 글에서는 트라이 자료구조를 활용하여 어떻게 검색어 자동완성 기능을 구현하는 지, 그리고 개선점들을 발견하여 해결하는 과정에 초점을 맞춰 작성해보겠습니다.
1. 요구사항/설계 범위 정리
해당 책의 내용은 면접 상황을 가정하고 쓰여져 있어, 다음의 요구사항을 만족하면서 검색어 자동완성을 구현해주어야 합니다.
요구사항
- 응답 속도가 빨라야 함 : 검색어 한단어씩 입력할 때마다 자동 완성되어야 하므로, 응답 속도가 빨라야 합니다. 보통 100ms이어야 사용자가 불편함을 느끼지 않는다고 합니다.
- 결과가 정렬되어야 함 : 자동 완성 결과들이 특정 기준(검색 빈도 등)에 의해 정렬되어야 합니다.
- 규모 확장 가능/고가용성 : 많은 트래픽을 감당해야 하고, 시스템이 계속 사용 가능해야 합니다.
서비스 규모 추정/가정
- 인간 사용자 : 1000만명
- 한 사용자의 일간 검색 횟수 : 매일 10건 검색
- 한 번 검색할 때마다 평균 20바이트의 문자를 검색
- ASCII 사용, 1문자당 1byte
- 평균 4단어, 각 5글자 ⇒ 20byte
- 검색어 단어를 하나씩 입력할 때마다 API 전송
search?q=a/search?q=ap/search?q=app/ …- 20단어이면 20번의 API 전송
이러한 가정이라면 초당 총 질의(QPS)는 다음과 같습니다.
(1000만 사용자 _ 10 검색 횟수 _ 20글자) / 일(24시간) / 3600초 = 약 24,000
책에서는 최대 QPS는 이에 2배를 더해 48,000으로 해주었고, 질의 중 20%를 신규 검색어로 가정해주었습니다. 따라서 매일 0.4GB가 새롭게 DB에 추가되는 상황을 가정하였습니다.
2. 시스템 설계
우선 시스템 설계는 크게 2가지 파트를 중점으로 생각해볼 수 있습니다.(= 시스템 설계 초안)
- 검색어 질의를 수집해야 합니다.
- 사용자가 검색하면 해당 문자로 시작하는 인기 검색어 n개를 정렬해주어야 합니다.
트라이 자료구조
검색어 자동완성을 위해 사용할 자료구조는 트라이 자료구조입니다. 문자열을 저장하기에 최적화된 자료구조입니다. 트라이는 이진탐색보다 문자열 탐색할 때 훨씬 빠르게 접근할 수 있습니다.
- 트라이 : 문자열들을 간단히 저장할 수 있는 자료구조
- 루트는 빈 문자열
- 각 노드의 자식 노드는 최대 26개(영어니까, 다음 문자도 26개만 가능!)
- 문자를 찾기까지는 문자열의 길이만큼의 시간복잡도, O(M)
예를 들어, max라는 단어를 찾는 경우, 다음과 같은 탐색 과정을 거치게 됩니다.
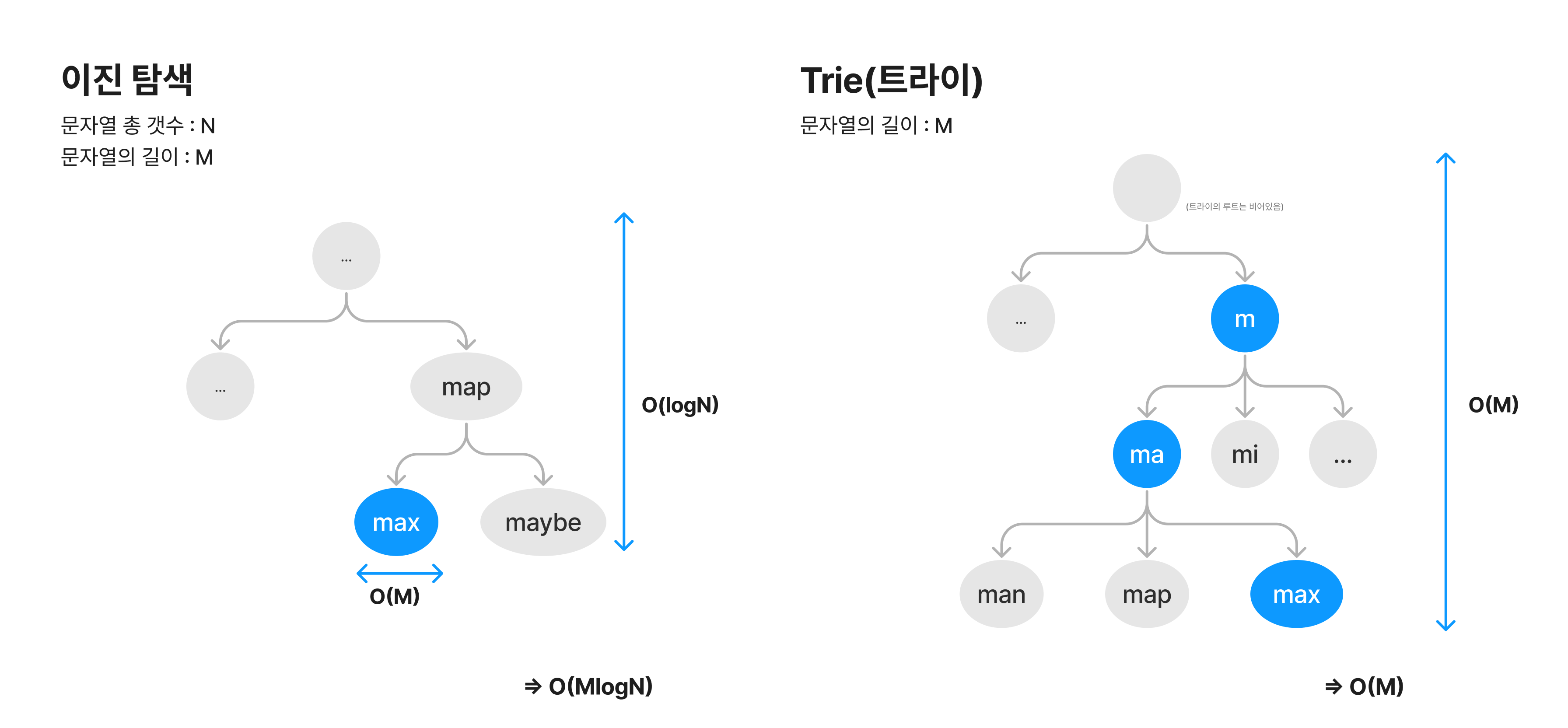
다음의 상황일 때 이진탐색과 트라이의 시간복잡도를 비교해보면, (문자열 총 갯수 : N, 문자열의 길이 : M) 이진 탐색은 찾는 노드까지 가는 시간 O(logN), 그리고 해당 노드의 문자열이 내가 찾는 문자열인지 확인하는 시간 O(M)이 걸려서 총 O(MlogN) 이 걸리게 됩니다.
반면, 트라이는 매 노드마다 하나의 알파벳만 저장합니다. 매 노드마다 현재 문자열의 위치와 같은 알파벳 노드를 찾아서 탐색을 이어갑니다. 따라서 문자열의 길이만큼의 깊이까지 탐색하여, 총 O(M) 이 걸리게 됩니다.
위의 기본 트라이 자료구조에는 검색 빈도가 따로 저장되어있지 않기에, 총 검색 시간은 O(M)이 걸립니다. 검색어 자동 완성 시, 검색 빈도 순서로 정렬해주기 위해서 트라이 자료구조에 빈도도 함께 저장해주겠습니다. 다음과 같은 구조가 됩니다.
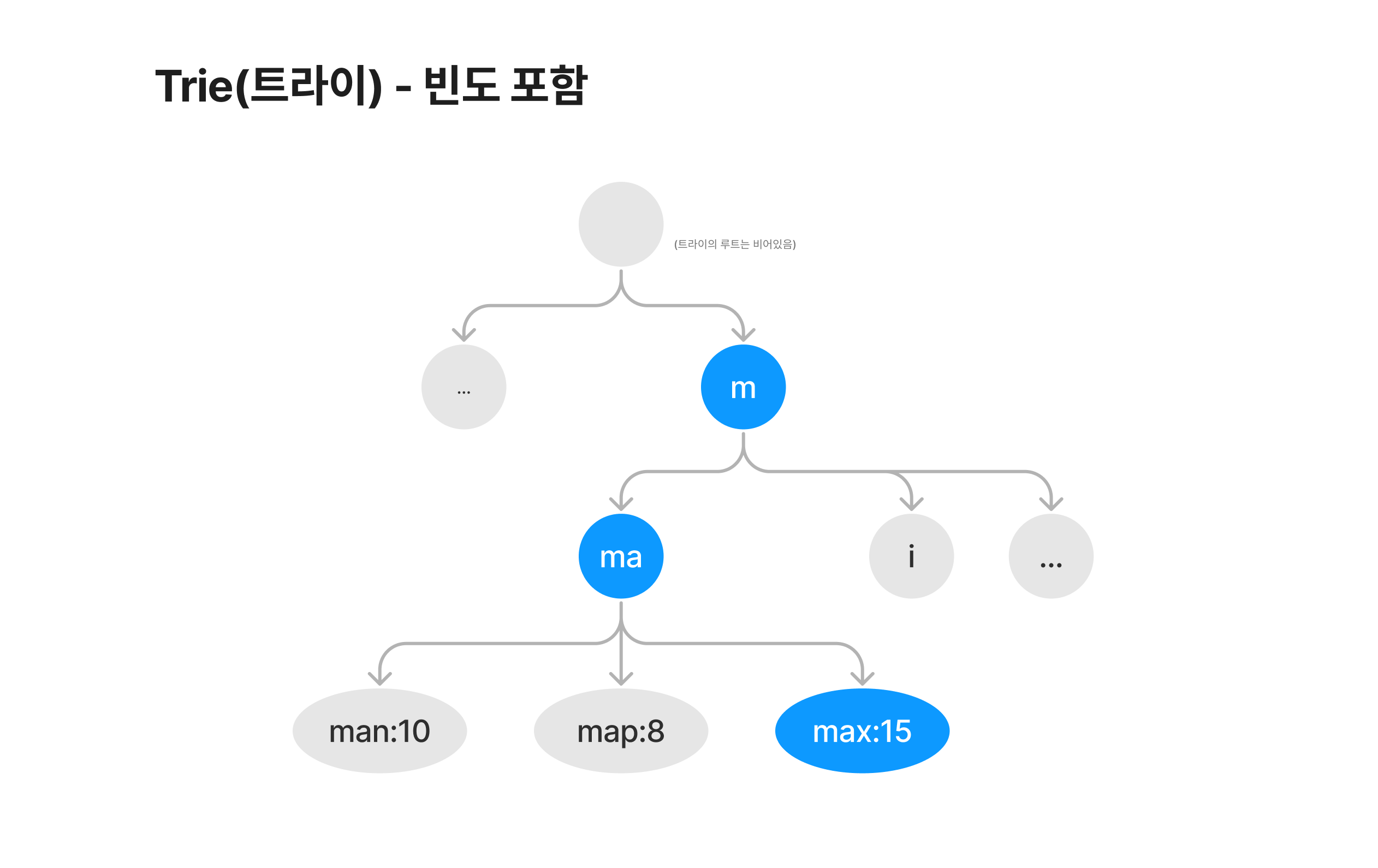
여기까지의 트라이 구조로 인기 검색어 k개를 찾는 순서와 시간 복잡도는 다음과 같습니다.
(접두어의 길이 M / 주어진 노드의 자식 노드 갯수 C)
- 접두어가 담긴 노드를 찾는다 ⇒
O(M)(문자열의 깊이만큼 탐색) - 해당 노드의 자식 트리를 탐색한다 ⇒
O(C)(자식 트리의 토드 총 갯수) - 자식 트리의 노드들을 인기순으로 정렬하여 인기 검색어를 찾는다 ⇒
O(ClogC)(정렬하는 시간복잡도)
⇒ 결과적으로 찾는 시간 복잡도는 O(M) + O(C) + O(ClogC)입니다.
개선점?
기본적으로 위와 같은 구조로 검색어 자동완성 기능을 구현할 수 있으나, 다음의 문제를 개선해주면 시간 복잡도를 훨씬 개선해줄 수 있습니다.
a. 모든 길이의 문자열에 대한 자동완성을 저장해주어야 한다는 점
만약 입력된 모든 길이의 문자열을 저장하게 된다면 굉장히 비효율적입니다. 사용자가 검색하는 문자열의 길이는 무한정 길지 않으므로, 최대 n자 이상은 접두어로 트라이에 저장해줄 필요가 없습니다. 어차피 자주 검색하는 단어는 n자 이하일 것이고, 자동 완성 기능은 해당 길이에만 서비스해주면 충분합니다.
b. 매번 인기 검색어를 정렬해주어야 한다는 점
검색할 때마다 해당 빈도수를 업데이트하고, 인기 순서를 재정렬해주어야 하는 과정이 비효율적입니다.
이를 각각 개선해주겠습니다.
개선 1. 검색어 최대 길이 제한하기
사용자가 검색하는 검색어는 무한정 길지 않기 때문에 자동 완성은 짧은 단어에만 제공해주어도 충분합니다. 만약 특이하게 긴~ 단어 조합을 검색한다면 특수한 상황이기에 굳이 해당 단어를 접두어로 자동 완성해줄 필요가 없기 때문입니다. 책에서는 접두어의 최대 길이를 50으로 한정하였습니다.
이로 인해 기존에 해당하는 노드까지 찾는 시간이 O(N)에서 최대 50으로 제한됩니다. 즉, 시간복잡도가 O(N)에서 O(1)로 단축됩니다.
개선 2. 노드에 인기 검색어 캐싱하기
매 검색마다 검색어의 빈도를 업데이트하고 빈도순대로 정렬해주는 건 비효율적입니다. 이를 개선하기 위해서 노드별로 하위 트리의 인기 검색어들을 캐싱해줄 수 있습니다.
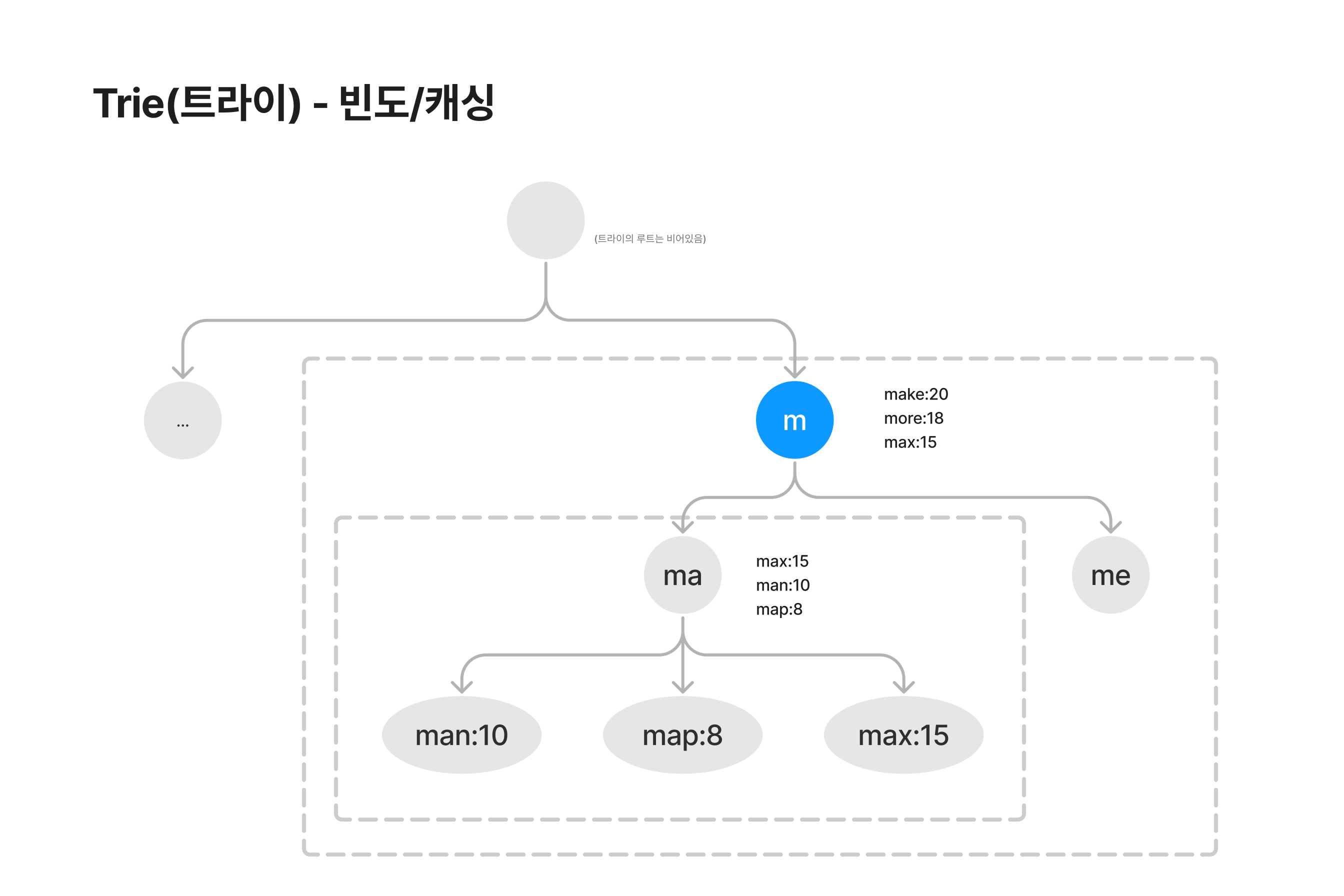
즉, 위의 2가지 개선으로 인해 총 시간 복잡도는 다음처럼 단축됩니다. (트라이의 최대 깊이 제한/정렬하는 시간 단축)
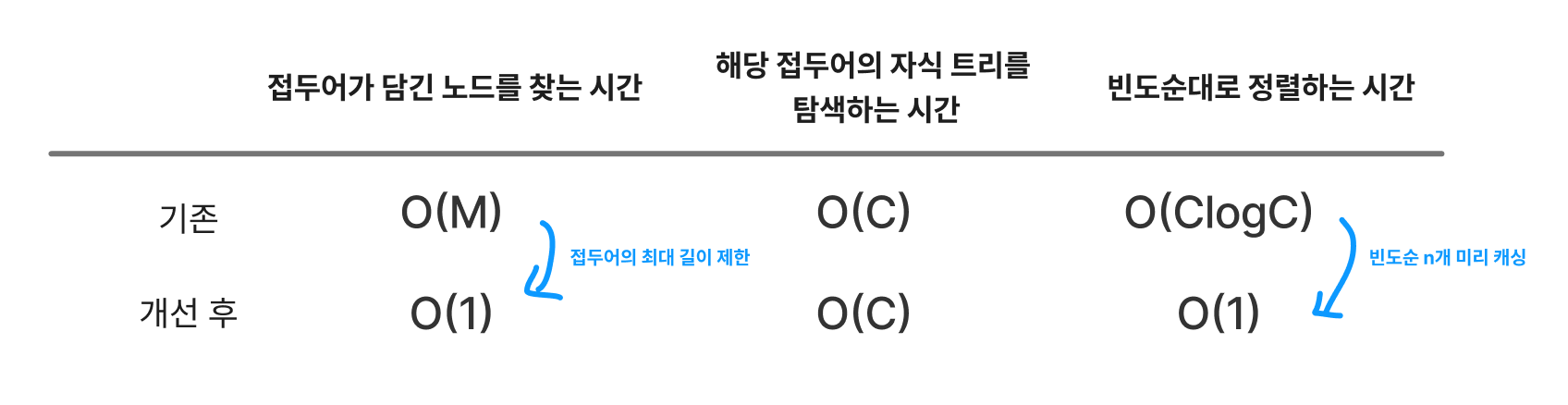
개선 3. 트라이 갱신 주기 정하기
만약 트라이 갱신(트라이 DB 업데이트, 인기 검색어 캐싱 업데이트)이 사용자들의 검색마다 매번 이루어지면 많은 오버헤드가 발생할 수 있습니다. 만약 실시간성이 중요한 서비스라면 매번 검색 질의마다 트라이가 갱신되는 게 효율적이지만, 그렇지 않다면 비효율적일 수 있습니다.
예를 들어, 트위터는 실시간성이 강한 서비스이므로(인기 검색어가 하루에도 여러 번 확확 바뀜) 검색 질의마다 매번 업데이트를 해주는 게 의미가 있지만, 구글 검색같은 경우는 트위터보다는 실시간성이 덜하므로 트라이를 자주 갱신해줄 필요는 없습니다.
만약 실시간성이 중요하지 않은 서비스라면, 모든 질의마다 매번 트라이를 갱신해줄 필요는 없고, 인기 검색어는 자주 바뀌지 않으니까 자주 갱신할 필요는 없습니다. 오히려 오버헤드가 발생하고 질의 자체가 느려질 수 있습니다. 따라서 갱신 주기를 설정해주는 게 효율적입니다. 만약 트라이 갱신 주기를 1주일이라고 정한다면, 다음처럼 동작하게 할 수 있습니다.
- 사용자의 검색 질의를 저장 (데이터 분석 서비스 로그 → 로그 취합 서버 → 취합한 데이터)
- 워커 서버가 1주일마다 트라이 DB/캐시를 업데이트해줍니다.
결과적으로 다음과 같은 과정으로 인기검색어가 조회/저장됩니다.
- 인기 검색어 조회 : 트라이 캐시를 통해 이뤄짐
- 인기 검색어 저장/수정 : 1주일마다 워커 서버를 통해서 이뤄짐
추가적으로 생각해볼 것들
- 트라이 데이터베이스 선택하기
- 문서 저장소 : 트라이 갱신이 주기적으로 이뤄지므로, 직렬화하여 DB에 저장할 수 있음
- 키-값 저장소 : 해시 테이블 형태로 키(문자) : 값(빈도수)으로 저장할 수 있음.
- 자동 완성은 빨라야 한다 ⇒ 프론트쪽에서 캐싱 등을 활용하는 것도 고려해보기
- AJAX 요청 : 새로고침하지 않아도 자동완성되어 빠르게 보여줄 수 있음.
- 브라우저 캐싱 : 인기 검색어는 업데이트가 빠르지 않으므로 미리 캐싱해두고 주기적으로 업데이트 해줄 수 있음.
- 데이터 샘플링 : 모든 질의를 로깅하지 않고, N개중 1개만 로깅하도록 설정해주기.
- 트라이 갱신 방법
- 매주 한번 갱신 : 새로운 트라이를 만들고 기존 것을 대체하기.
- 각 노드를 갱신 : 트라이가 작을 때 고려해볼 방법으로, 빈도수가 업데이트된 노드의 부모노드를 따라가서 업데이트해주기! 성능이 좋지 않아 큰 트라이에는 부적합할 수 있음.
- 서버 확장해줄 경우
- a~x까지의 알파벳을 분할하여 서버에 분담해주기
- n개의 서버를 사용할 수 있다면, a~x까지 n개의 그룹으로 분할하여 저장해주기
- 각 접두어가 똑같은 검색어 양이 아니기 때문에, 과거 질의 데이터의 패턴을 활용해서 분할해주기
여기까지 검색어 자동완성을 위한 트라이 자료구조/문제 해결과정을 정리해보았습니다. 만약 실제 구현을 한다면 Elasticsearch을 사용하거나(?) 트라이를 몽고 디비에 저장하고 워커서버를 사용해서 매주 업데이트를 해주지 않을까 싶은데…후에 좀 더 알아보고 프로젝트에 적용해보려고 합니다. 우선 이번 글에서는 해당 내용에서 시간 복잡도를 개선하는 과정이나 트라이 자료구조 ↔ 이진 탐색의 비교, 문제를 발견하고 해결법을 선택하는 과정 등을 정리해보았습니다.